Articles
Fireside Chat with Philip Tetlock
Fireside Chat with Philip Tetlock
Philip Tetlock is an expert on forecasting. He’s spent decades studying how people make predictions — from political pundits to CIA analysts. In this conversation with Nathan Labenz, he discusses a wide range of topics, including prediction algorithms, the long-term future, and his Good Judgment Project (which identified common traits of the most skilled forecasters and forecasting teams).
Below is a transcript of the EA Global conversation between Tetlock and Nathan Labenz, which we have edited lightly for clarity. You can also watch this talk on YouTube or read its transcript on the EA Forum.
Labenz: It’s exciting to have you here. A lot of audience members will be familiar with your work and its impact on the EA community. But about half are attending EA Global for the first time, and may not be as familiar with your research.
We're going to correct that right now. To start off, let’s go back in time, break down your research into a few chapters, and talk about each one to provide a short introduction. Then, we will turn toward topics that are [timely] and of practical interest to the EA community.
Your first breakthrough book was called Expert Political Judgment. In it, you summarized a systematic approach to evaluating expert political judgment. Maybe you could start by sharing your principal conclusions in doing that research.
Tetlock: Sure. The book’s full title is Expert Political Judgment: How Good Is It? How Can We Know? The latter two parts are critical.
I became involved in forecasting tournaments a long time ago. It's hard to talk about it without revealing how old I am. I had just gotten tenure at [the University of California,] Berkeley. It was 1984 and I was looking for something meaningful to do with my life. There was a large, acrimonious debate going on at the time about where the Soviet Union was heading. Its old generation of leadership was dying off: Brezhnev, Andropov, and Chernenko. Gorbachev was just about to ascend to the role of General Secretary in the Politburo.
It's hard to recapture states of ignorance from the past. The past is another land. But trust me on this: The liberals, by and large, were very concerned that the Reagan Administration was going to escalate the conflict with the Soviet Union to the point of a nuclear confrontation, or a nuclear war, for that matter. There was a nuclear freeze movement and a great deal of apocalyptic talk. Conservatives’ views were in line with those of Jeanne Kirkpatrick, ambassador to the United Nations under Reagan, who believed the Soviet Union was an infallibly self-reproducing totalitarian system that wasn't going to change.
Neither side proved to be accurate about Gorbachev. Liberals were concerned that Reagan was driving the Soviets into neo-Stalinist retrenchment. Conservatives thought, “We’ll be able to contain and deter [the Soviets], but they're not going to change.” Nobody expected that Gorbachev would institute reforms as radical as the ones that he did — reforms that ultimately culminated in the disintegration of the Soviet Union six years later. Nobody was even [close to being] right. Nonetheless, virtually everybody felt that, in some fashion, they were. Conservatives reformulated the events. They said, “We won the cold war. We drove [the Soviets] to transform.” Liberals said, “It would have happened anyway. Their economy was crumbling and they recognized that, as Gorbachev once said to Shevardnadze, ‘We can't go on living this way.’”
Each side was well-positioned to explain, with almost 20/20 hindsight, what virtually everybody had been unable to see prospectively. It was this asymmetry between hindsight and foresight that led me to believe it would be interesting to track expert political judgment over time.
The first people we studied were Sovietologists. I had some colleagues at UC, Berkeley and elsewhere who helped with that work. There was also some foundation support. We've gradually been able to cobble together increasingly large forecasting tournaments. And, using big collections of data from 1988 and 1992, the book came out in 2005. The upshot was that subject-matter experts don't know as much as they think they do about the future. They are miscalibrated. It's difficult to generalize, but when [experts] say they are 85% confident [in a prediction], it happens roughly 65% or 70% of the time. Some of them are considerably more overconfident than that.
I think this led to the misconception that I think subject-matter experts are useless. I don’t believe that. But there are some categories of questions in which subject-matter experts don't know as much as they think they do, and other categories in which they have a hard time doing better than minimalist benchmarks. Examples include simple extrapolation algorithms and — to name an analogy that particularly bugs some of them — the dart-tossing chimpanzee [i.e., the notion that chimpanzees who make predictions by randomly throwing darts at a set of options fare as well or better than experts in some areas].
Labenz:[To recap,] principal findings of that research were that people are overconfident, and that there's much less to be gained from expertise, in terms of the ability to make accurate forecasts, than experts would have thought.
Tetlock: Yes. I remember one of the inspirations for this work. When [Nobel Prize-winning behavioral economist] Daniel Kahneman came to Berkeley in 1988, and I described the project to him at a Chinese restaurant, he had a clever line. He said that the average expert in my studies would have a hard time outperforming an attentive reader of the New York Times.
That is, more or less, an accurate summary of the data. Educated dilettantes who are conversant in public affairs are not appreciably less accurate than people who are immersed in the subject domain.
That really bothered a lot of people. Still, I think that finding doesn't give us license to ignore subject-matter experts. I'd be glad to talk in more detail later about what I think subject-matter experts are good for.
Labenz: From there, you take that startling observation that the attentive reader of the New York Times can at least compete with experts and you get involved in a forecasting tournament put on by IARPA [Intelligence Advanced Research Projects Activity]. Sometime around 2011, I joined your team. That ultimately led to the book Superforecasting.
Tell us about the structures you created so that people like me could sign onto a website [and participate as forecasters]. By the way, you did a great job on the website.
Tetlock: I had nothing to do with that [the website]. There are so many critical things I had nothing to do with — it’s a very long list. [Tetlock laughs.]
Labenz: Putting a team together was certainly a huge part of it. You created a structure with different experimental conditions: some people work by themselves, some are in teams, some have different training. Could you walk us through the Good Judgment Project team that ultimately fueled the book Superforecasting?
Tetlock: The project was very much due to the work of someone who is linked to the EA community: Jason Matheny of IARPA, a research and development branch of the intelligence community that funded these forecasting tournaments on a scale that was far more lavish than anything to which I'd been accustomed.
I divide the work into two lines. The earlier line of work is about cursing the darkness. The later line of work is more about lighting candles. The earlier line of work documented that subject-matter experts fall prey to many of the classic cognitive biases in the judgment decision-making literature; they are overconfident, as we just discussed. Also, they don't change their minds as much as they should, and in response to contradictory evidence are susceptible to hindsight bias. Sometimes their probability judgments are incoherent. There are a lot of cognitive biases that were documented in Expert Political Judgment. That's why I [describe the work as] “cursing the darkness.”
The superforecasting project was much more of a challenge. How smart can people become if you throw everything you know at the problem — the whole kitchen sink? It wasn't a subtle psychological experiment in which you try to produce a big effect with a little nudge. It was a very concerted effort to make people smarter and faster at assigning probability judgments to achieve a tangible goal. That is when the forecasting tournament that IARPA sponsored took place. There were a number of big research teams that competed, and we were one of them. It was a “lighting the candles” project, and we threw everything we could at it to help people perform at their optimum level.
There were four categories of strategies that worked pretty well, which we fine-tuned over time:
- Selecting the right types of forecasters, with the right cognitive ability and cognitive style profiles.
- Providing various forms of probabilistic reasoning training and debiasing exercises.
- Facilitating better teamwork.
- Using better aggregation algorithms.
Each of those categories played a major role.
Labenz: Let’s talk briefly about each one. First, who are the right people? That is, what are the cognitive profiles of the most successful forecasters?
Tetlock: I wish I had a slide that could show you Raven's Progressive Matrices. It is a devilishly tricky test that was developed in the 1930s and is a classic measure of fluid intelligence — your ability to engage in complex pattern recognition and hypothesis testing. It was used by the U.S. Air Force to identify farm boys who had the potential to become pilots, but couldn't read. There’s no [linguistic] interface. You simply look at it and determine whether a pattern fulfills the requirements. It has nothing to do with politics or language. And it proved to be an important factor; fluid intelligence is not to be underestimated.
That doesn't mean everybody has to have an IQ of 150 in order to be a superforecaster. They don't. But it does help to be at least a standard deviation above the norm in fluid intelligence.
The other factors had more to do with your style of thinking and how you think about thinking; they didn't have to do with raw crunching power. Active open-mindedness — in the earlier work we called it “foxiness” — is your willingness to treat your beliefs as testable hypotheses and probabilistic assertions, not dogmatic certainties. If you're willing to do that, it’s a good sign that you're interested in becoming more granular.
There's an old joke in [the field of] judgment decision-making: Deep down, people can only distinguish between three degrees of certainty: yes, no, and maybe. But to be a really good forecaster in these tournaments, you needed to be granular. You needed to be like a world-class poker player. You needed to know the difference between a 60/40 bet and a 40/60 bet, or a 55/45 bet and a 45/55 bet. Depending upon the domain, you can become very granular. Some domains are more granular than others, but you can almost always do better than just “yes, no, or maybe.” The worst forecasters were more in the “yes, no, maybe” zone. Their judgments are either very close to zero, very close to one, or very close to 0.5. It was all binary [for them].
So, [we sought] people who had reasonable scores in fluid intelligence and who were actively open-minded. The final factor was just a matter of curiosity and a willingness to give things a try. The kinds of questions IARPA was asking us in this tournament were about the Syrian Civil War, and whether Greece was going to leave the Eurozone, and what Russia was going to do in Crimea. There were questions about areas all over the world: the South China Sea, North Korea, Germany. There were questions about Spanish bond yield spreads. It was an incredible, miscellaneous, hodgepodge of questions.
Some people would say to us, “These are unique events. There's no way you're going to be able to put probabilities on such things. You need distributions. It’s not going to work.” If you adopt that attitude, it doesn't really matter how high your fluid intelligence is. You're not going to be able to get better at forecasting, because you're not going to take it seriously. You're not going to try. You have to be willing to give it a shot and say, “You know what? I think I'm going to put some mental effort into converting my vague hunches into probability judgments. I'm going to keep track of my scores, and I'm going to see whether I gradually get better at it.” The people who persisted tended to become superforecasters.
Labenz: That is essentially a Bayesian approach. You don't need a large set of potential outcomes in order to be able to make a prediction, because you have your priors and, as you said, you are willing to change your mind and update your beliefs accordingly.
This is a bit of an aside, but what is happening when people take a collection of facts and then spit out a number? Do you have any insight, for example, into how people choose between 0.65 and 0.7 when they're trying to assess the likelihood of something like Bashar al-Assad staying in power for a certain amount of time?
Tetlock: It's very context-specific. Most of the news is pretty granular. What's the probability of Trump being reelected? Maybe it's between 35% and 55%. But then there's a gaffe or a scandal and [the odds might] go down a bit. Maybe it appears that Biden will be [Trump’s opponent] and [Trump could have] a harder time defeating Biden than someone else, so Trump’s chances go down. Various things happen and you adjust.
One of the interesting things about the best forecasters is they're not excessively volatile. There’s an interesting division in the field of judgment decision-making between those who say people are too slow to change their minds — too cognitively conservative — and those who say people are excessively volatile. That second group point to the stock market. Robert Shiller is famous for making that argument.
Both views are true. Some people are excessively conservative sometimes and, at other times, excessively jumpy. The path to doing well in forecasting tournaments is to avoid both errors. [When we train forecasters,] the second prong of our approach is about helping people engage in what we call an “error balancing process.” We don't just hammer away at them if they are overconfident. Pushing people down just leads to underconfidence. They need to be aware of the risk of both and appreciate that it's a balancing act. We try to sensitize people to the conflicting errors to which we're all susceptible when we try to make sense of a wickedly complex, environment.
Labenz: How do you encourage people to work in teams? And how did the best algorithm teams work together? What made a great team?
Tetlock: The best teams were skillful at improvising divisions of labor, but that was more of an administrative [accomplishment]. Still, it is important, and we didn't give them much help with it. What guidance we did give them, the best teams took seriously.
I would say the most important attribute was the capacity to disagree without being disagreeable — to learn how to state your disagreements with other people in ways that don’t push them into a defensive corner. People are psychologically fragile. And conversations are not just information exchanges. Truth-seeking is rarely the dominant goal. In most conversations, the dominant goal is mutual face-saving. We help each other along. And when one of us stumbles, being nice means we help preserve their social identity and reputation for being a good partner. We preserve the social compact.
That often means that if you say something stupid, I say, “Yeah, interesting.” I don't try to unpack it and say, “Why, exactly, do you think that?” Great team members have the ability to engage in reasonably candid exchanges, in which people explore the assumptions underlying their beliefs and share those perspectives. They have the ability — and the willingness — to understand another person’s point of view so well that the other person says, “I couldn't have summarized my position any better than that.”
Everybody in the room would probably agree that perspective-taking is important. But I’ll bet many of you wouldn't enjoy trying to engage in perspective-taking for John Bolton, the current national security advisor [this conversation took place before John Bolton was fired]. You might not want to summarize his views on Iran or North Korea in such a way that he would say, “That is a concise and accurate understanding of my views.” Many of you would say, “I think I'd rather slit my wrists.”
Labenz: It’s the John Bolton intellectual Turing Test. It’s probably not super-appealing to most of us.
Tetlock: Or imagine perspective-taking for someone more extreme than John Bolton. Try to see the world from Kim Jong Un’s point of view.
Labenz: That sounds challenging, to say the least. So, [good team members] disagree without being disagreeable, and can accurately summarize their teammates’ positions and pass intellectual Turing Tests.
On top of that, you added a layer of algorithmic optimization. Will [MacAskill] spoke a little bit, in his opening remarks, about the challenge of becoming clones of one another. If we are all clones of one another, then we can't use our similar beliefs as reinforcement. And what you found in forecasting was that when people are cognitively diverse, you were able to synthesize their beliefs and arrive at more accurate predictions. You combined them in a clever way. Tell us how you did that.
Tetlock: We had wonderful support from some very insightful statisticians like Lyle Ungar, Emile Servan, and Jon Baron. They deserve the credit for these algorithms.
The core idea is fundamentally simple. Everybody has heard about “the wisdom of the crowd” and how the average of the crowd tends to be more accurate than the majority of the individuals who contributed to that average. That is common knowledge now.
To take it one step beyond that, you use the most recent forecast and the best forecast to create a weighted average. That will do better than the unweighted average.
The third step [comes into play in cases in which] the weighted average contains more information than you realized. That happens when people who normally disagree with each other suddenly start agreeing, and those numbers are flowing into the weighted average.
It’s not that people who think similarly are producing the weighted average. There's some cognitive diversity. The example I'm fond of is from the movie Zero Dark Thirty, in which James Gandolfini is playing former CIA director Leon Panetta. If you haven't seen the movie, it's worth watching; it contains a really great example of how not to run a meeting and how not to use probabilities.
Imagine that you're the CIA director and each of your advisors is providing a probability estimate of how likely it is that Osama bin Laden is in a particular compound in the Pakistani town of Abbottabad. Each of them says there is a probability of 0.7.
What aggregation algorithm should the director use to distill the advice? The question you need to ask first is: How cognitively diverse and independent are the perspectives represented in the room? If there are five people and each of them arrives at 0.7 using a different type of information — cybersecurity, satellite reconnaissance, human intelligence, and so forth — and they're in a siloed organization in which nobody talks to anybody else, what is the true probability? They've independently converged on 0.7. And they say it was not mathematically deducible from the information given, but can be statistically estimated if there are enough forecasters making enough judgments on enough topics.
That's what the statisticians did. The answer in our case was to turn 0.7 into roughly 0.85. That's aggressive and you run risks doing that. But it proved to be a very good way of winning the forecasting tournament.
Labenz: In other contexts, I’ve heard you call that extreme-izing the views of your most trusted advisors. Is that what ultimately produced the very best forecast over time?
Tetlock: It did. But it did occasionally crash and burn.
Labenz: What's an example of a time when extreme-izing went awry?
Tetlock: There were a number of methodological shortfalls of the IARPA tournaments. They used a timeframe. With a forecast, if you are given less and less time for Bashar al-Assad to fall, or less and less time for Spanish bond yield spreads to hit a certain threshold value, you should gradually move your probability downward. Sometimes they move down too quickly and take a hit because something would happen at the last minute.
Labenz: I’d like to touch on a few other projects that you've been involved with more recently. You were involved in a tournament that pitted humans against machines and human-machine hybrids against each other. And you're now involved in another IARPA project called FOCUS [Forecasting Counterfactuals in Uncontrolled Settings], which I think is currently going on. So I'd love to hear a little bit about those two, starting with your experience with the humans-versus-machines (and hybrids) tournament.
Tetlock: I'm not a formal competitor in the hybrid forecasting competition, so I don't have too much to say about that, except that the algorithms have a very hard time getting traction on the kinds of questions IARPA likes to ask. If you ask algorithms to win board games like Go or chess, or you use algorithms to screen the loan worthiness of customers for banks, algorithms wipe the floor with the humans. There's no question about that.
When you ask algorithms to make predictions about the current Persian Gulf crisis and whether we are going to be at war with Iran next week, they're not very helpful. This goes back to the objection that you can't assign probabilities to some categories of events because they're too unique.They're not really quantifiable. And the algorithms do indeed struggle and the humans are able to do better than the algorithms in that sort of context.
Is that always going to be so? I don't like to say “always.” I suspect not. But right now, given the state of the art, it may be that bank loan officers and derivatives traders should be worried about their jobs. But should geopolitical analysts? I'm not so sure. I don't think so.
Labenz: Tell us a little bit about the FOCUS project that you're now involved with as well.
Tetlock: That represents an interesting turn. It is a project that addresses something that has been of great interest to me for decades: the problem of counterfactuals and how difficult it is to learn from history. It is psychologically difficult to grasp how reliant we are on counterfactual assumptions when we express casual opinions that seem factual to us.
After 1991, if you had asked conservatives what happened with the demise of the Soviet Union, they would have confidently said, “We won. Reagan won the Cold War.” And liberals would have said, “The Soviet economy was imploding, and that's just the way it happened. If anything, Reagan slowed it down. He didn't help.”
People act as if those statements aren't counterfactual assertions. But upon close inspection, they are. They are based on the assumption that if Reagan had not won the election against Jimmy Carter and been inaugurated in January 1981, and a two-term Carter presidency and a two-term Mondale presidency had unfolded instead, then the Soviet Union’s demise would have happened exactly the same way. That is awfully speculative. You really don't know. Counterfactuals are the soft underbelly of humans’ political and economic belief systems.
If people become more rigorous and thoughtful, they can ideally become more accurate. They should also become better at extracting lessons from history. That, in turn, should make you a better conditional forecaster — if you're extracting the right causal lessons. But how do you know you're getting better? You can't go back in a time machine and assess what Reagan did or didn’t do.
The so-called “solution” that IARPA has come up with is to rely on simulated worlds. They have chosen the video game Civilization 5 for the FOCUS program. How many of you have heard of that? [Many audience members raise their hands.] Oh my heavens. How interesting. Civilization 5 has several functional properties that make it interesting as a base for IARPA’s work. It has complexity, path dependency, and stochasticity or randomness. Those are key features that make the real world extremely hard to understand, and they exist in Civilization 5. What is different in the world of the game is data availability. You can assess the accuracy of counterfactual judgments in the simulated world of Civilization 5 in a way that is utterly impossible in the real world. That was the lure for IARPA.
Once again, teams compete, but not to generate accurate forecasts about whether there's going to be a war in the Persian Gulf. They compete to determine whether different civilizations — the Incas and the Swedes, for example — will go to war. You have to be very careful about transferring real-world knowledge into the Civilization 5 universe. It has its own interesting logic. That's also part of the challenge: How quickly can teams adjust to the simulated world and learn to make more accurate counterfactual judgements?
We're beginning to use other simulated worlds, too. We're doing a little bit of work, for example, with Bob Axelrod on an iterated Prisoner's Dilemma game. These games are easy to understand without noise. But when there's noise, all hell breaks loose. So we're interested in people's ability to master various simulated worlds. And the leap of faith is if you get really good at reasoning in these simulated worlds, you'll be able to do better in the actual world. That will be the ultimate validation: if participants return to the real world and are better at counterfactual reasoning. [Our goal is] to train intelligence analysts by having them go through these protocols so that they are subsequently better at making conditional forecast judgments that can perhaps save save lives and money.
Labenz: I think that is interesting and relevant to the EA community. One of the movement’s early intellectual foundations was to make an impact. And that's inherently a counterfactual exercise, right? What would have happened if bednets were not distributed, or if children were not dewormed, or if cash transfers were not handed out? It is a big challenge to come up with rigorous answers in the real world, where you don't have access to concrete answers about what would have happened otherwise.
Tetlock: I think those questions are easier to answer because you can do randomized controlled trials. There is a control group. And when you have a control group, you don't need the counterfactuals anymore. Counterfactual history is, in a sense, imaginary control groups that we construct when we're in a data-poor environment.
Labenz: That's fascinating. A lot of that work has been done. And as the movement has evolved over the last three to five years, there has been a shift. We have run randomized controlled trials where we can.
But at some point, you run out of things that are easily testable. You have a portfolio of incredible winners, such as bednets, that are like the Google and Facebook equivalents of charity. But then you need to find new areas, especially as the movement gets bigger and attracts more resources. Now we have a bit of a blank canvas and a really huge problem space.
So, I think counterfactual reasoning starts to get to some of the hardest questions that the EA community is facing. I'd love to talk about a few dimensions of that problem. One has to do with ambiguity. In the forecasting tournaments that you've described, there is a clear outcome: either the bond spreads hit the threshold or they don’t, or Assad is in power or he's not. But so many things of tremendous importance are much more ambiguous. It’s difficult to clearly state what did happen. How have you thought about tackling that challenge? Or, if you haven't tackled it, what are lessons that come out of the more structured challenges that could be applied to much more ambiguous situations?
Tetlock: I'm not quite sure I understand the question. But I do think that meditating on historical counterfactuals is a useful form of consciousness-raising. I'm not talking about social science fiction, like The Man in the High Castle, which I think is a different form of an interesting thought experiment.
I think historical counterfactuals are a very useful way of sensitizing you to your ignorance. They are a useful corrective to overconfidence. When you understand that the causal propositions driving your forecast rest on assumptions that are debatable, you tend to become better calibrated. Sometimes the counterfactual assumptions are not as debatable because they rest on — if not randomized controlled trials — very sophisticated econometric tests. In that case, a bit more confidence may be justified. But being aware of how much credence is reasonable to put in the soft underbelly of your belief system is a useful form of consciousness-raising.
Labenz: Another challenge for the EA community: It can be hard to calibrate your effort when considering long time horizons or low-probability events. What will the population of the world be in 300 years? That is a question that is important to a lot of people in the room. They feel that if it's a thousand times what it is now and there is an opportunity to impact that outcome, then they should care about it a thousand times as much. But [there is the issue of] low discounting. When things get either very rare or very far into the future, it is tough to think about developing good judgment.
Tetlock: I was just at Ted Nordhaus’s Breakthrough Institute meeting at Cavallo Point. There were a lot of people at that meeting who are specialists in climate and population, and who had models of what the world might be like in 2100, or even 2300. These were aggressive, long-range forecasts way beyond anything we look at. In doing political judgment work, our longest forecast is for five to 10 years, and in our work with IARPA, the longest forecasts are 18 to 24 months. Most of them are 12 months ahead or less.
How do you bridge these short-term forecasting exercises with the need to engage in longer-term societal planning? Maybe one of the more radical implications of a lack of accuracy in short-term forecasting is that long-range planning does not make sense. What are you planning for if you can't forecast very much? That makes some people very upset. The Intergovernmental Panel on Climate Change, for example, has forecasted out to the year 2100. That forecast is one of the key underpinnings of concern about climate change. You have nitpickers who say you can't really predict anything.
You can predict some longer-term things if there is a very strong science base for them. And of course, that is the argument made about climate change and, to some degree, population. However, the spread of estimates on population is surprisingly wide.
We've been developing a methodology we call “Bayesian question clustering,” which is designed to bridge the gap between short- and medium-term forecasting so that people can get feedback on the accuracy of their judgments on a human timescale.
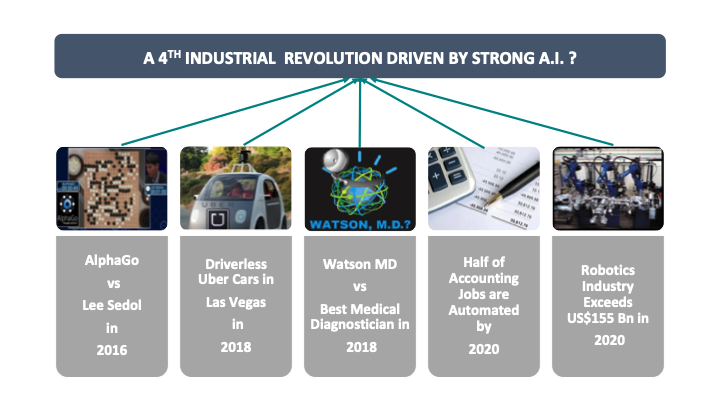
This [Tetlock refers to the slide] is one of those “big Davos nosebleed abstraction” things. [Tetlock laughs.] Are we on a trajectory for AI to drive a fourth industrial revolution, which will dislocate major white-collar labor markets by 2040 or 2050? I won't have to worry about it [I’ll likely be retired], but maybe this audience has reason to be concerned. And what would you expect to observe in 2015 or 2016 if we were on that trajectory? You might expect AlphaGo to beat the world Go champion in 2016.
That happened. Does that mean we're on a trajectory toward this grand scenario [of AI driving a fourth industrial revolution]? No, it doesn't. But does it increase the probability? Yes, a little bit. And these questions [on the slide] were nominated by subject-matter experts. It’s not that each of these micro-indicators has some diagnosticity vis-a-vis the ultimate outcome: the driverless Uber cars picking up people in Las Vegas in 2018 for fares (not just as an experiment); Watson MD beating the world's best medical diagnosticians in 2018; half of the accounting jobs in the U.S. becoming automated by 2020 (that's somewhat under the control of Congress, of course); robotics industry spending exceeding $155 billion in 2020. [These milestones are meant to indicate how] fast we may be on the road to that particular scenario. And I think the answer is: The future is coming, but more slowly than some people might have thought in 2015.
Will there be widespread autonomous robotic warfare by 2025? Here are several indicators people developed and the likelihood ratio associated with each.
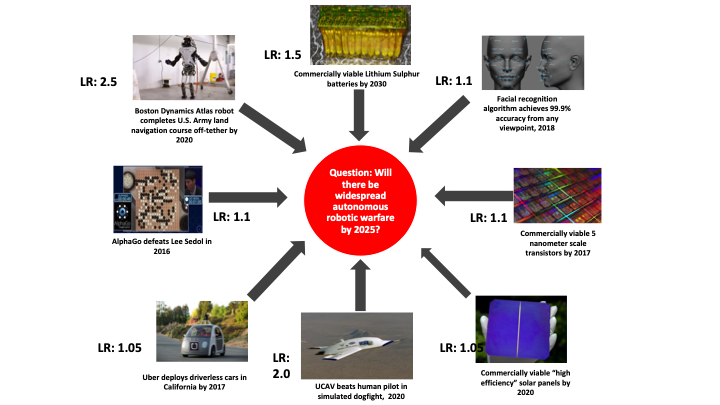
There are two indicators that seem to be most indicative. One is Boston Dynamics’ ATLAS robot completing an Army land navigation course off-tether by 2020. That has a likelihood ratio of 2.5, which means that if we are on that scenario trajectory, departing significantly from 1.0 is informative. Similarly, there is a likelihood ratio of 2.0 [for that scenario trajectory] if an unmanned combat aerial vehicle defeats a human human pilot in a simulated dogfight by 2020.
You can think of this as almost a Terminator scenario and how close we are to a world in which these kinds of mechanisms are, without our direction, launching attacks. A lot of things having to do with battery life, face recognition, and the sophistication of transistors would have to happen. There is a whole series of indicators.
I’m not going to claim that this series is correct. It hinges on the accuracy of the subject-matter experts. But I do think it's a useful exercise for bridging short- to medium-term forecasting with longer-term scenarios and planning. If you want to stage a debate between Steve Pinker-style optimists and doomsters, and ask what infant mortality in Africa will look like in the next three, five, or 10 years, [you could try this type of approach].
Labenz: Just to make sure I understand the likelihood ratios correctly: Do they come from the correlations among forecasters?
Tetlock: They are specified by subject-matter experts.
Labenz: So they are taken as an input.
Tetlock: Yes, it's essentially an input to the model. And by the way, it comes back to the question at the beginning of this conversation: What are subject-matter experts good for? One of the things they are really good for is generating interesting questions. I’m not so sure they’re good at generating the answers. But they are good at generating questions.
Labenz: Speaking of interesting questions, you mentioned the upcoming election earlier. Is there a way to use some of these techniques to get a handle on how important something like the next election might be? Can we use this kind of conditional forecasting to tell us what really matters so that we can focus on trying to impact particular outcomes?
Tetlock: I don't know how many of you have heard of Duncan Watts. He's brilliant. He just wrote a paper for Nature on predicting history, a text-analysis project that goes back at least 100 years. What did people in 1900 think were really important [events] that would be remembered by people in 2000 or 2020? And which events did people in 2000 and 2020 actually think were important? When we are immersed in the present, there's a strong tendency for us to think many things are extremely important, but people in 50 or 100 years do not find them important.
It raises an interesting question: Who's right? It could be that we, in the present, are highly aware of how contingency-rich our environment is, and how there are dramatically different possible worlds lurking. If we have an election that goes one way or the other, or if the economy goes one way or the other, or if there's a war in the Persian Gulf, will that be huge? Or will it be a footnote in history 100 years from now, or maybe not even a footnote?
Duncan Watts’s article is lovely. It is a methodologically beautiful example of the use of text analysis. It shows these interesting asymmetries in how we look at the world and it is a form of consciousness-raising. It helps us calm down a bit and look at ourselves as part of a longer temporal continuum, which is, of course, a problem a lot of people have with our work and forecasting tournaments. They think it induces “analysis paralysis” among activists, because it's very hard to build up momentum around something like climate change.
For example, if I think there's a 72% chance the IPCC is correct about climate change, am I a climate-change believer or am I a denier? What kind of creature am I who would say such a thing? A pain in the butt! Somebody who is obstructing political discourse and political progress.
Duncan Watts’s paper suggests that what we think is important is probably not going to stand the test of time very well. But there are exceptions: the discovery of DNA, the atomic bomb, Hitler. People at the time saw those as big events and they were right. But people are more often wrong than right [in assessing what is “big” as it is happening].
Labenz: So if you think something in your moment in history is important, you're probably wrong. Most things are not that important. But some things are.
If I'm trying to make a decision about how involved I want to be in a particular problem, like the upcoming election, should I go to a team of superforecasters and pose conditional questions? For example: If Trump wins versus somebody else, how likely is a war with Iran? How likely is a nuclear exchange? And should I then trust that to guide my actions, or would I be extending the power of superforecasting too far?
Tetlock: I'm not sure that superforecasting, as it is currently configured, is ready for prime-time applications. I think it would need to be ramped up considerably. You would want to have a very dedicated group of good forecasters who were diverse ideologically working on that. And I don't think we have that infrastructure at the moment. I think, in principle, it is possible, but I wouldn't recommend that you do it within the current structure.
Labenz: That could be a potential EA project. One of the big preoccupations of this community is identifying the right things to work on. That is a vexing problem in and of itself, is even before you get to the question of what can be done.
We don't have much time remaining, but I want to give you the chance to give some advice or share your reflections on the EA community. You were on the 80,000 Hours podcast, so you are at least somewhat aware of the community — a group that is highly motivated but wrestling with hard questions about what really matters and how to impact outcomes.
Tetlock: One thing that is a bit disconnected from the work we've been talking about on forecasting tournaments is related to what I call the “second-generation tournament.” The next generation of tournaments needs to focus on the quality of questions as much as the accuracy of the answers.
Something that has always interested me about EA is this: How utilitarian are you, really? I wrote a paper in 2000 called “The Psychology of the Unthinkable: Taboo Trade-Offs, Forbidden Base Rates, and Heretical Counterfactuals.” It was about the normative boundaries that all ideological groups, according to my model, place on the thinkable. There are some things we just don't want to think about. And effective altruism implies that you're willing to go wherever the utilitarian cost-benefit calculus takes you. That would be an interesting exception to my model. So I'm curious about that.
I've had conversations with some of you about taboos. What are the taboo cognitions [in the EA community]?
Audience member: Nick Bostrom wrote an article about the hazards of information and how some knowledge could be more harmful than helpful.
Tetlock: Yes. And Cass Sunstein makes arguments along those lines as well. Are there some things we're better off not knowing? Is ignorance better? I think very few of us want to know the exact time we're going to die. There are some categories of questions that we just don't want to think about. We'd prefer not to engage.
But I had more specific issues in mind. Are there some categories of things where members of the EA community just don't want to engage? I was having a conversation in the green room with an interesting person who is involved in animal rights. She seemed like a lovely person. I think there is a significant amount of interest in animal rights and animal suffering, and I know there are many libertarians and a fair number of social democrats in the EA community, but are there any fundamentalist conservatives? Are there people who are concerned about abortion? Would the cause of fetal rights be considered beyond the pale?
Audience member: It’s not beyond the pale.
Tetlock: I'm not the most socially sensitive person, but I’ve worked in a university environment for 40 years. I’m going to guess that 99% of you are pro-choice. How many of you would say that [fetal rights as a cause] is beyond the pale?
Audience member: I had a conversation about it last night.
Tetlock: What topics might lie in the taboo zone? I suppose pro-Trump cognitions might be in the taboo zone — the idea that Trump has saved us from a nuclear war in the Korean peninsula because he's such a wheeler-dealer.
Labenz: I've certainly heard some sincerely pro-Trump positions at EA Global in the past. I do think you're facing an audience that is very low on taboos. I bet we could find at least one or two.
Tetlock: This is very dissonant for me. I need to find taboos. [Laughs.]
Labenz: Let’s go back to the original question. Let’s say we are a group that is genuinely low on taboo topics and willing to consider almost anything — maybe even fully anything.
Audience member: Human sacrifice?
Labenz: [Laughs.] Well, we need to watch out for the [trolley] thought experiment, right? But if we are open to most [lines of inquiry], is there a downside to that as well? And what sort of advice do you have for a group like this one?
Tetlock: It is probably why I really like this group. It pushes open-mindedness to a degree that I have not seen in many organizations. It’s unusual.
You can end with the Dilbert cartoon. It tells you how easily forecasting can be corrupted and why forecasting tournaments are such a hard sell.
