Articles
Paul Christiano: Current Work in AI Alignment
Paul Christiano: Current Work in AI Alignment
Paul Christiano, a researcher at OpenAI, discusses the current state of research on aligning AI with human values: what’s happening now, what needs to happen, and how people can help. This talk covers a broad set of subgoals within alignment research, from inferring human preferences to verifying the properties of advanced systems.
A transcript of the talk, which we have lightly edited for clarity, is below. You can also watch Paul’s talk on YouTube and discuss it on the EA Forum.
The Talk
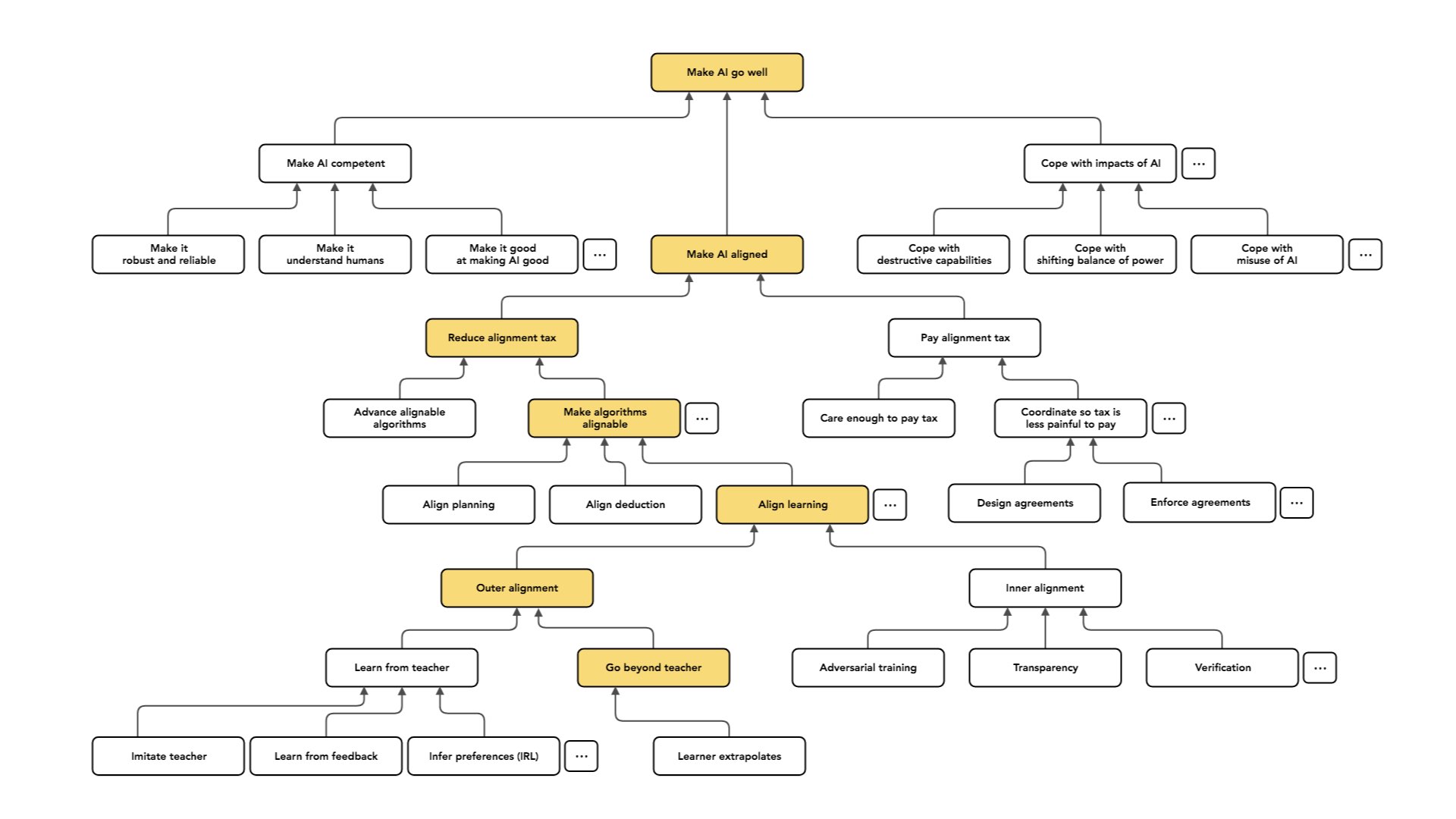
When I was preparing for this talk, I came to the view that it would be useful to describe how some of the pieces of AI alignment fit together — and how they relate to the broader project of making AI go well.
With that said, let's dive in. I'm broadly interested in the problem of making humanity's long-term future good. I'm zooming in on the sub-problem of the effects of AI on our long-term future and how to make those effects positive.
But even within that problem, there are many different sub-problems that we can think about separately. I think it is worth having some conceptual clarity [around those problems] and [pointing out the] distinctions [among them]. That's why there's a lot of empty space on this slide:

The part of the problem I most think about is what I call alignment.
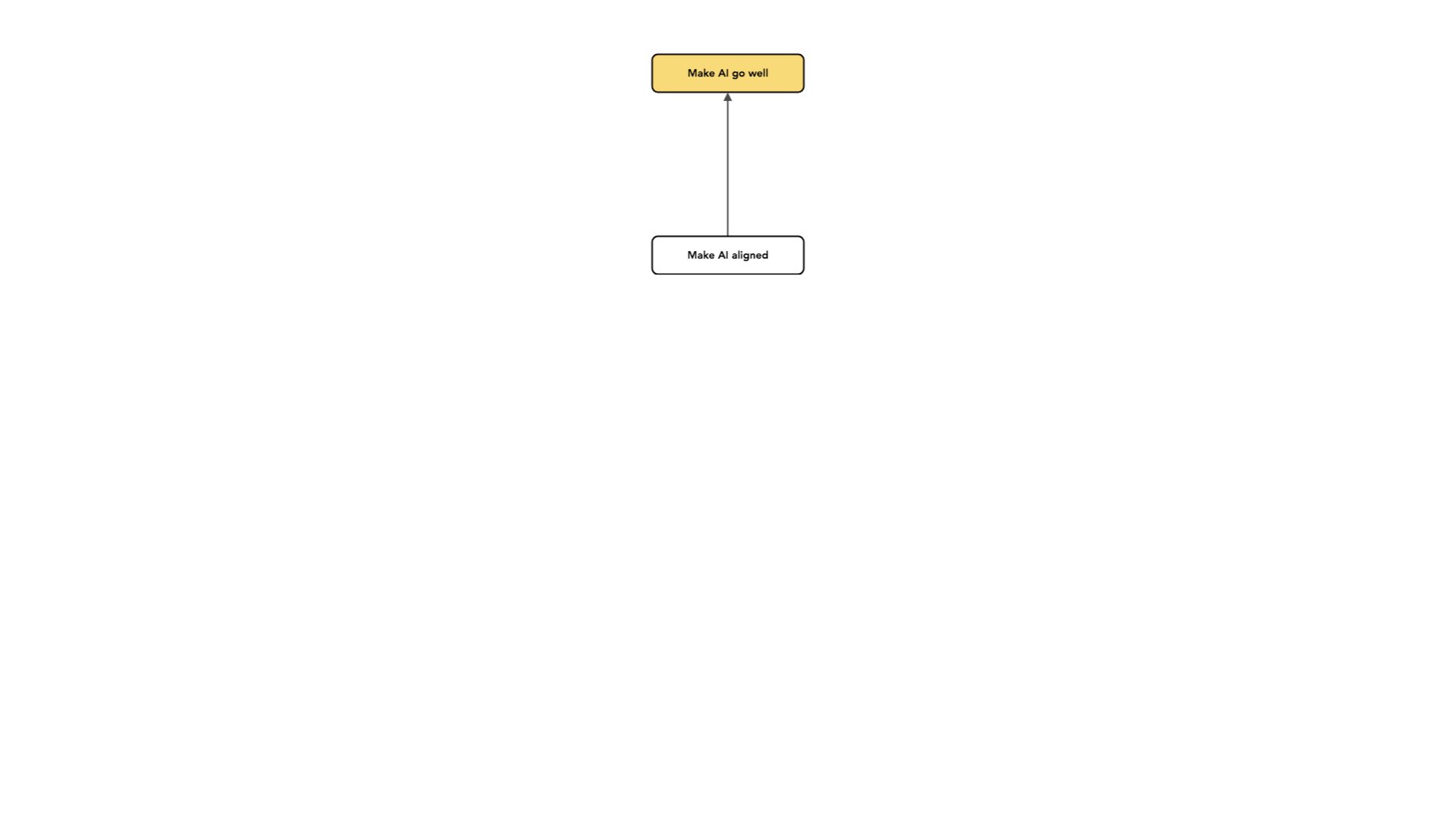
I use the concept of “alignment” in a slightly different way from other people.

What I mean is “intent alignment,” which is trying to build AI systems that are trying to do what you want them to do. In some sense, this might be the minimum you'd want out of your AI: at least it is trying. And intent alignment is just one piece of making AI have a positive, long-run impact. We want to avoid the situation where AI systems are working at cross-purposes to us and, as they become more competent, more effectively do stuff we do not want them to do. We want them to at least be trying.
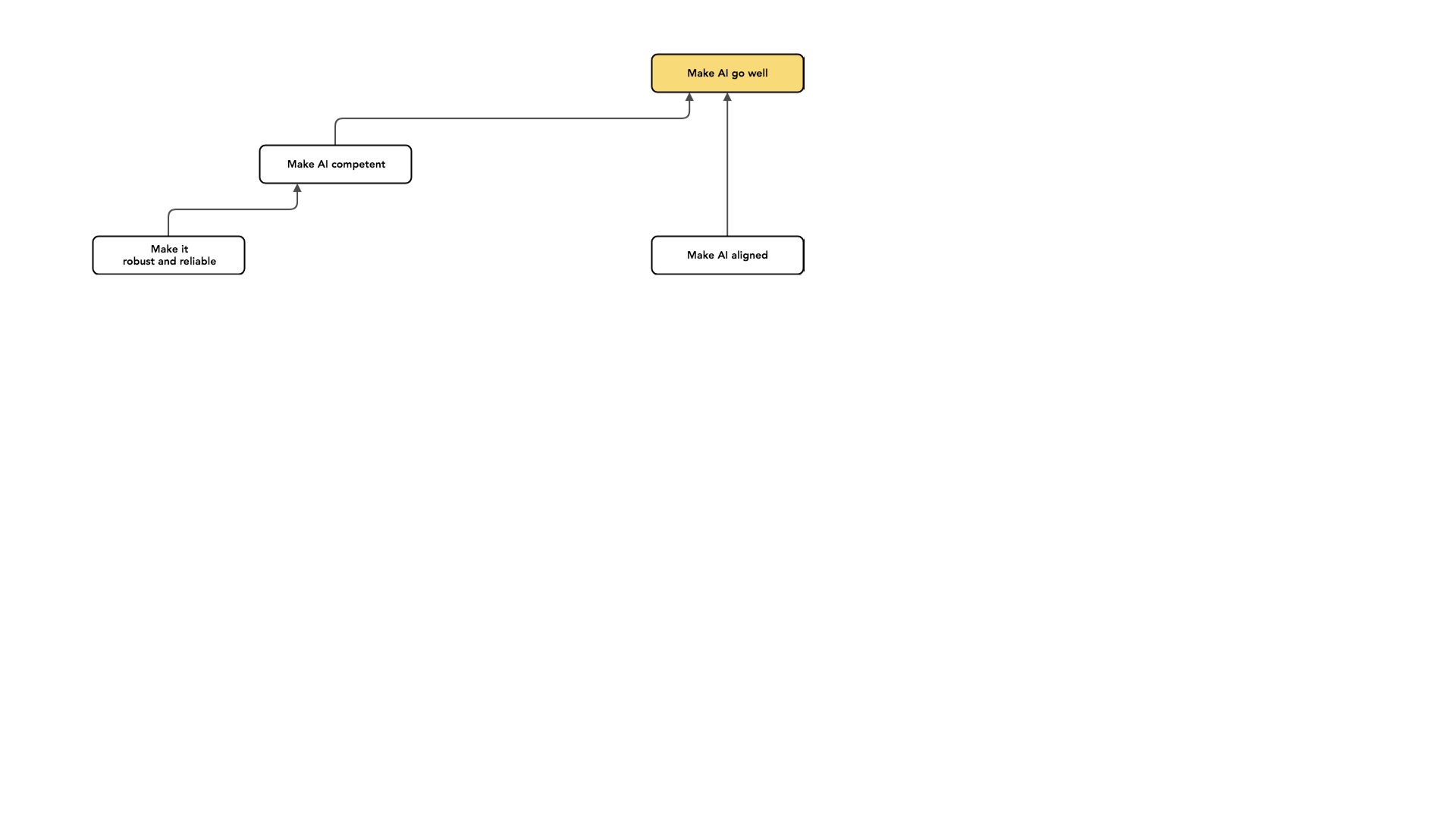
There are a lot of other problems we could work on with the same kind of intention. Another category of work is making AI more competent. Some forms of competence are mostly important over the short run, but even if we're exclusively focused on the long run, there are kinds of competence we care about.

An example is wanting our AI systems to perform reliably. A system can be well-meaning but unreliable. And if my system makes mistakes, those can potentially be very bad. For example, imagine I'm interested in the deployment of AI in high-stakes situations, such as making decisions about nuclear weapons. I might think it's really important for that new system to not mess up. I think this is a really important problem, but it's worth separating it from the problem of building AI that's trying to do what we want it to do.
Some techniques apply to both problems. But again, [it’s worth looking at] one of those problems and asking: “How can we solve this one?” I think that [reliability is something] we might hope will get better as our AI systems become more competent. So as AI improves, AI systems are better at understanding the world, and they're better at sort of doing what they're trying to do. We hope that not making mistakes [goes along with that].
I'm going to walk through a few more examples of competence that one could work on from the perspective of trying to make the long-run impacts of AI positive.
I'm choosing examples that feel close to intent alignment to be clear about what doesn't fall under this heading of intent alignment. Again, because I think having that distinction in mind [between intent alignment and competence] is helpful for thinking about work in this area.
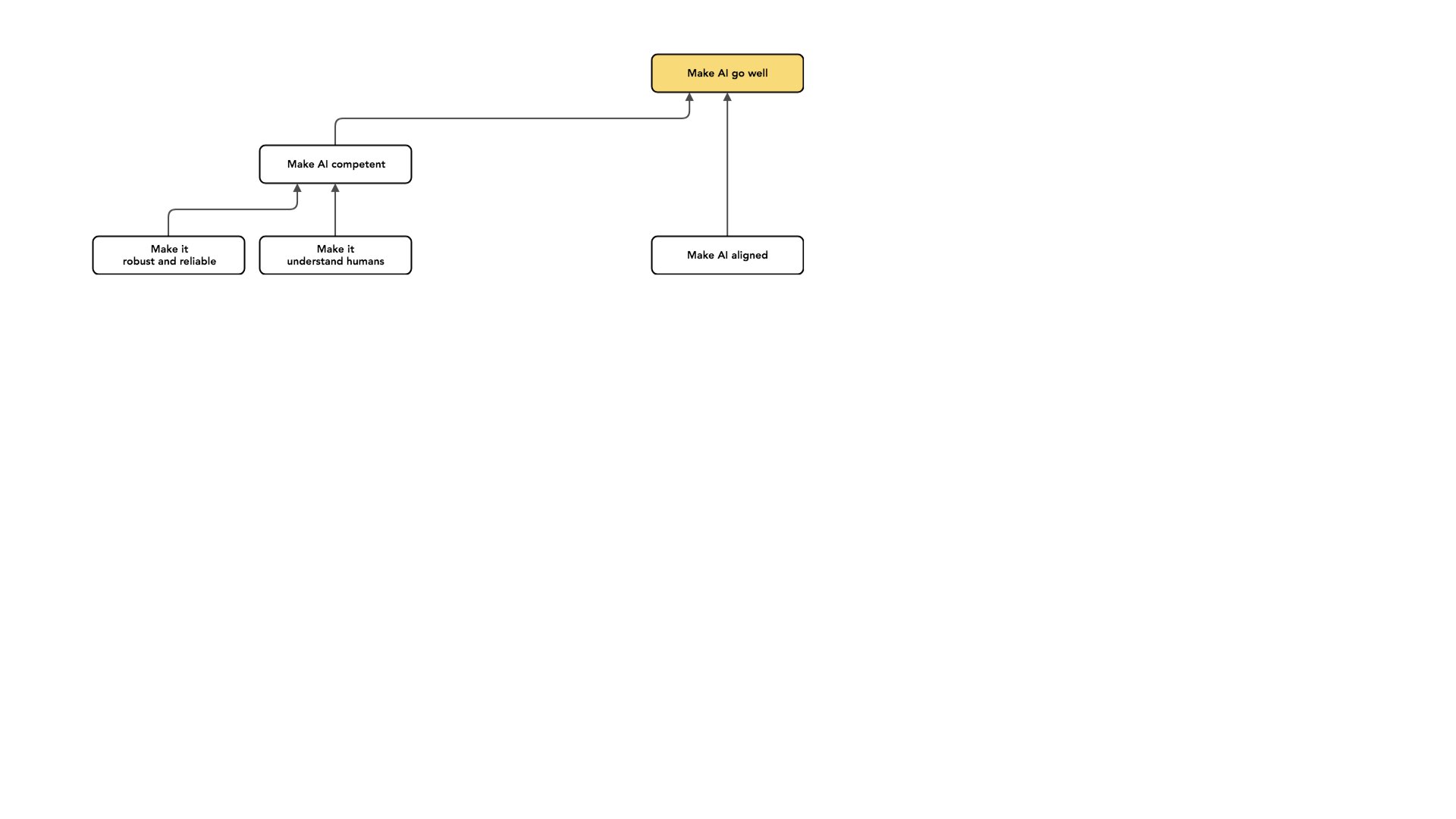
So another example that's maybe a little bit more surprising is having your AI understand humans well.

That is, there's this potential distinction between a system that is “well-meaning” (and is trying to do what I wanted to do) and a system that knows me well. If I imagine hiring an assistant, I could have an assistant who is trying to do the right thing, but maybe doesn't understand me very well or we don't have really high bandwidth communication, and this is another important but separate problem. That is, there's a distinction between [a well-meaning AI that’s trying to get what it thinks I want] and [an AI that really understands what I want].
And I mostly work on the well-meaning side of this rather than the “knows me well” side. One of the hopes that motivates that focus for me: I hope that you don't need a deep understanding of what humans want in order to avoid catastrophic bad outcomes.
If I imagine a scenario where an AI system is actively working against humans, [I might think about] tiling the universe with paperclips as an absurd example, and maybe in [a less extreme example, an AI] not allowing humans space to get what they want, or to figure out what they want and then ultimately get it.
Avoiding that case involves a minimal understanding of what it is that humans want. It involves understanding that humans don't want to be killed. Humans don't want you to take all their stuff and go run off. These are important facts that [we hope AI will understand early on as we make progress toward building more sophisticated systems]. When I say that an AI is trying to do what I want, [I mean that] it's trying to do what [it thinks that] Paul wants. It's not trying to do the thing that Paul in fact wants.
Okay. So that's an example of competence, which I think is important, and which I want to keep separate.
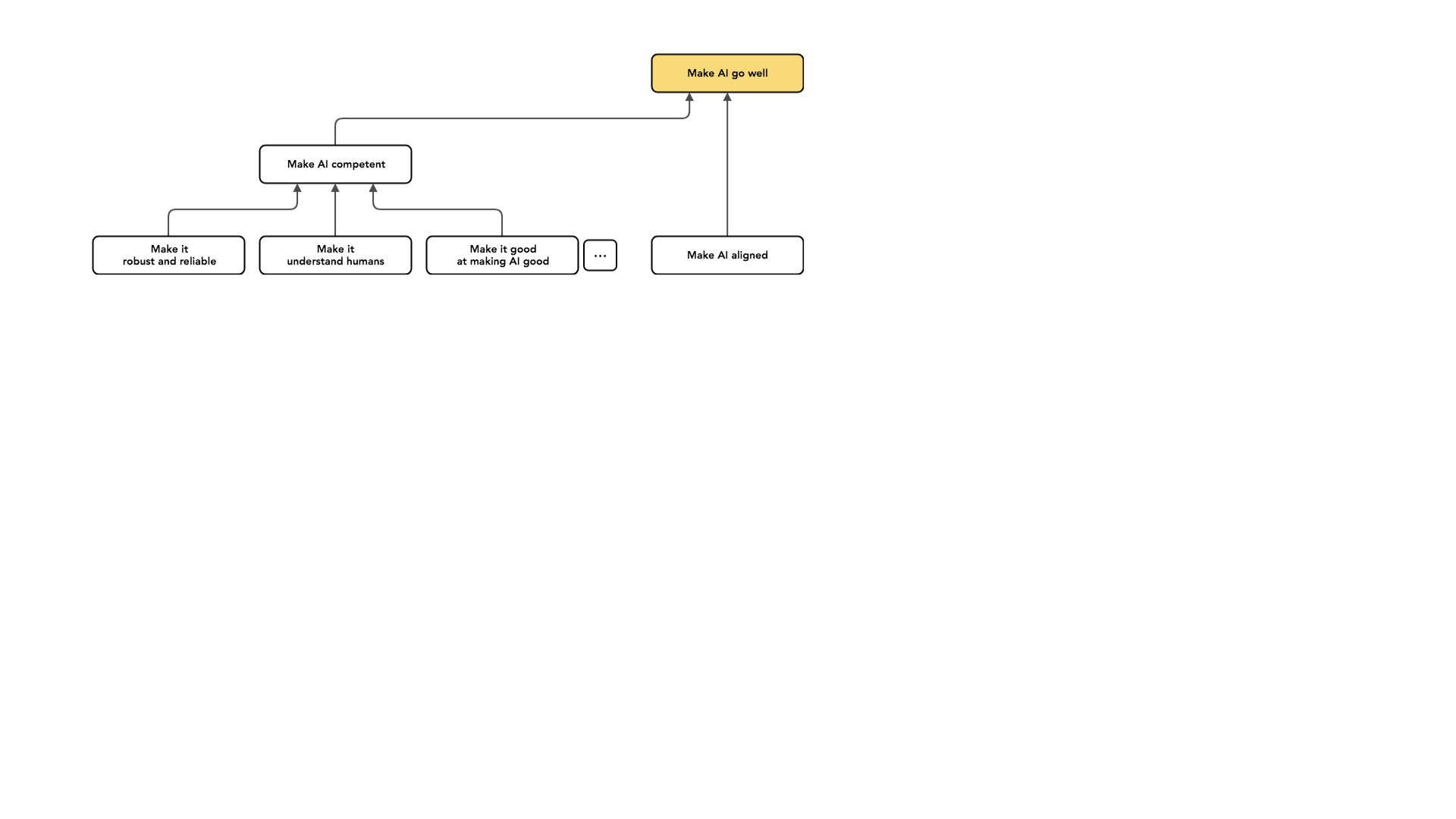
Another example that's maybe surprising is the distinction between making our AI good and having our AI help us make subsequent AI systems good. That is, we're sort of dealing with this handoff to AI systems right now.
We're going to be building AI systems that are going to be making some decisions on our behalf. That AI system we build will be helping us design future AI systems — or at some point, designing future AI systems on its own. And it will face its own similar problems as it [works on building aligned AI].
So you could imagine a case where we have built an AI that's doing what we want, but then messes up and builds another AI system that's not doing what [the first AI system wanted]. And I'm again distinguishing this problem from the challenge we face right now in this very first handoff, and I'm thinking about just this very first handoff [from humans to AI, rather than from AI to other AI].
These problems are similar. I also hope that that research will help future AI systems build subsequent AI systems that are aligned with their interests. But I think that our cognitive work right now could quickly become obsolete once we're thinking about systems much more sophisticated than us. And so I'm really focusing on this challenge [the human-AI handoff] — sort of the first challenge we face, the first step of this dynamic. So these are all in the category of making AI capable.
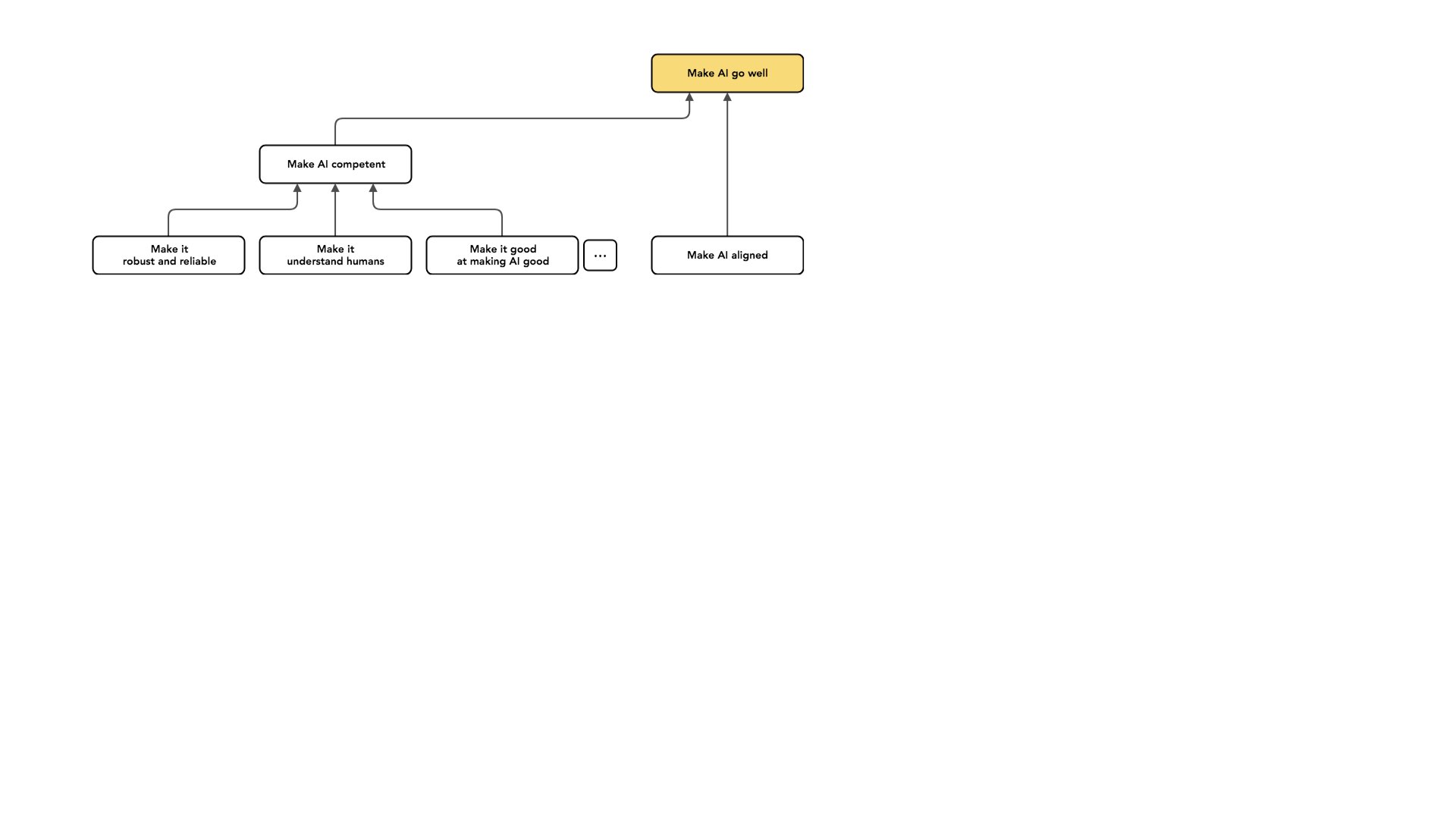
I think separating these problems from alignment problems is important to expressing why I view alignment as this sort of well-scoped problem that I'm optimistic we can totally solve. That's partly because I'm willing to say that [figuring out handoffs] is like a narrower problem than the overall problem of making AI go well. And many of these [issues] on the competence side, I sort of hope will get better as AI improves. I'm picking alignment [rather than competence] in part because I think it's the aspect of the problem that's most likely to not get better as AI improves.
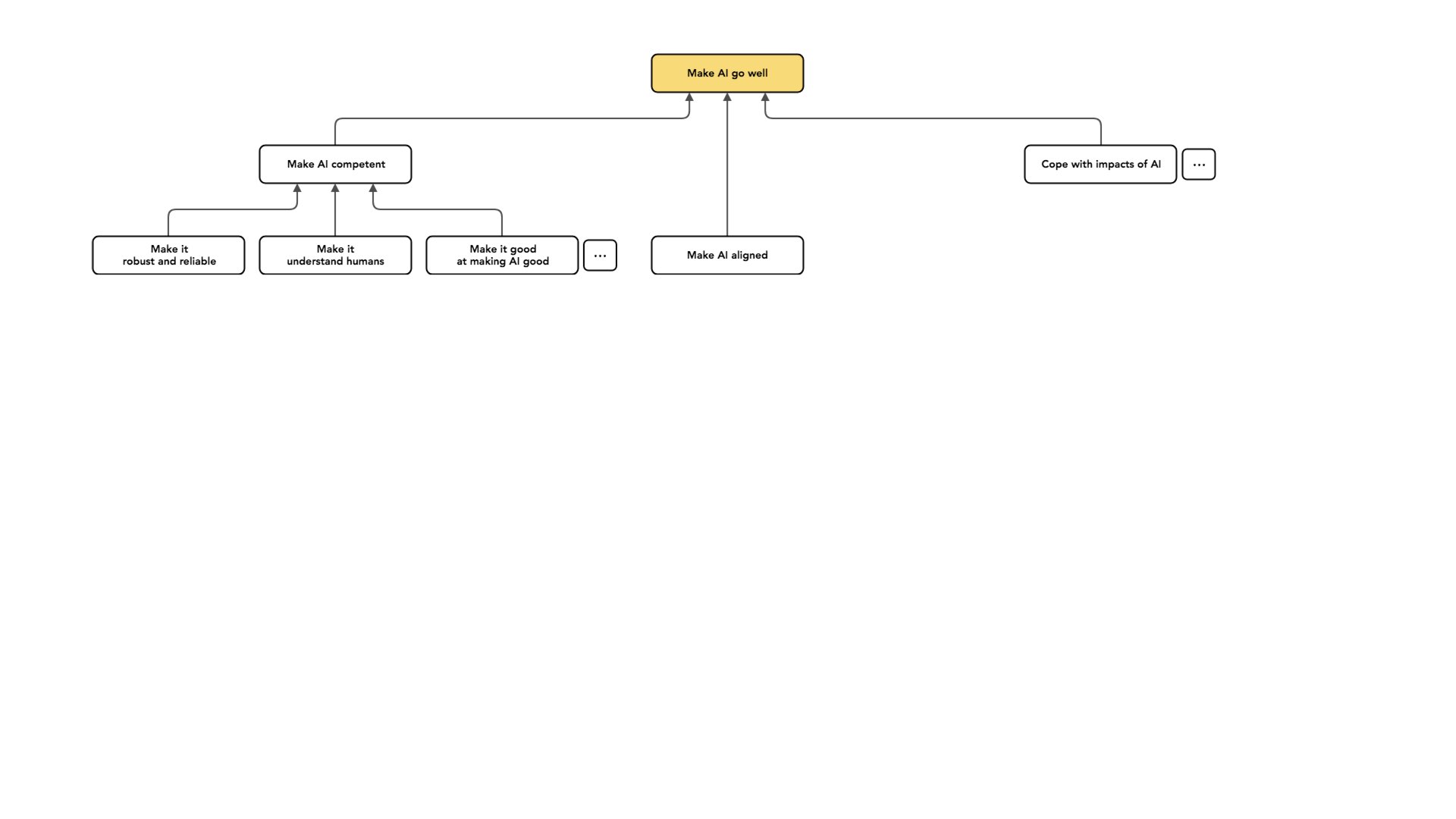
There's a whole separate category of work: Rather than changing the way my AI behaves or changing what my AI does, I can also try and cope with the impacts of AI systems.
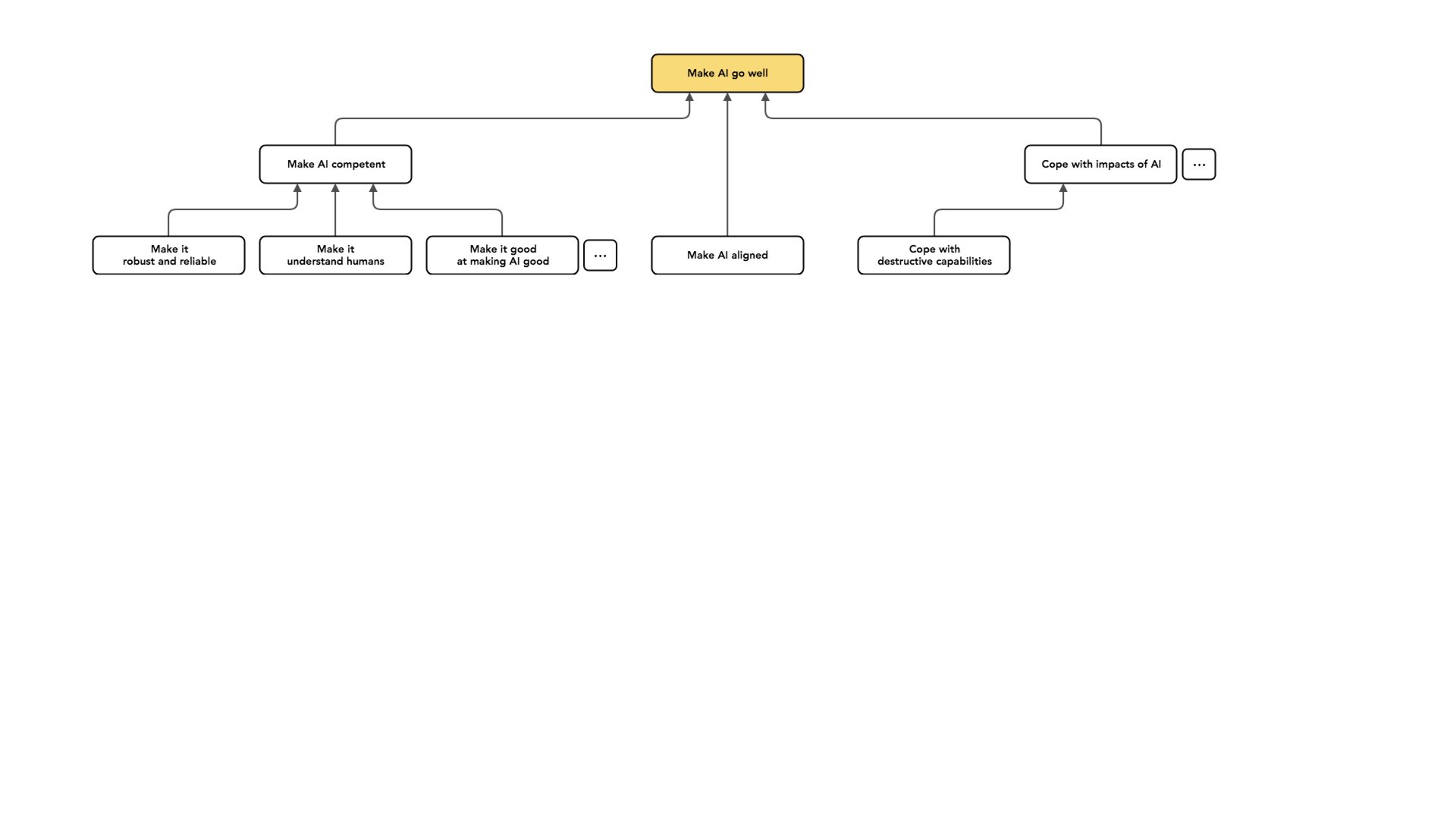
As an example, AI systems may enable new destructive capabilities, like maybe letting us make better bombs or make really big bombs more cheaply. Maybe they allow us to design bioweapons, something along these lines. I might say that [these capabilities] require new approaches to governance, but I want to keep those [considerations] separate from work on the character of AI.
Similarly, AI could cause shifts in the balance of power. It can enable certain kinds of misuse.
Say, maybe criminals currently have a hard time coordinating; this becomes easier in a world that requires only capital [to purchase AI systems that can facilitate crime], or maybe totalitarian regimes have an easier time sort of remaining in power without supportive people if more and more tasks are automated.
And there's a lot of dot, dot, dots in this graph [see slide above] because all of these nodes are covering only a very small part of the total possible space. I think these are some of the big areas that people work on: making our AI more competent, making our AI aligned so it's at least trying to do the right thing, and coping with the impacts of AI. These are all like different projects that one can engage in to try and make AI go well.

Once I've said that so many things are not AI alignment, a natural question may be: how could we even possibly fail at this problem? What could go wrong?
An example of a thing that could go wrong is that when we train ML systems, we often use some measurable objective to say which policies are doing better or worse. And you may end up with AI systems that, instead of trying to do what I want, are trying to optimize the kinds of measurable objectives that I use during training. So that's an example of a possible failure. And if what I want is not measurable, I may have this constraint imposed by the nature of the technology, which [makes it much easier to build systems that pursue measurable goals rather than the unmeasurable goals I want to fulfill].
Another possible failure is that there might be different kinds of values that behave well on the historical cases I use to train an AI system [but wouldn’t work well for real-world applications], which could lead to [the system acting in nonsensical ways]. ML might give me, in some sense, like a random draw from some distribution of values, and then I might be unhappy because most random draws of values aren't [similar to] mine.
I'm going to sort of zoom in more.
To think about dividing this problem further, I'm going to use an abstraction. I think this comes from Eliezer [Yudkowsky], though I'm not sure. I like this notion of an “alignment tax” — the language, at least, comes from Eliezer.

What I mean by this is that everyone would prefer to have AI systems that are trying to do what they want [the systems] to do. I want my AI to try and help me. The reason I might compromise is if there's some tension between having AI that's robustly trying to do what I want and having an AI that is competent or intelligent. And the alignment tax is intended to capture that gap — that cost that I incur if I insist on alignment.
You might imagine that I have two actors, Alice and Bob. Alice really wants to have an AI that is trying to do what she wants it to do. Bob is just willing to have an AI that makes as much money as it possibly can. You might think that if making money is an instrumental subgoal for Alice [helping her to get what she wants], Alice would want her AI to make more money [only] in the service of helping her achieve what she wants. Thus, Alice faces some overhead from insisting that her AI actually try to do exactly what she wants, and the alignment tax captures that overhead.
The best case is a world in which we have no alignment tax: [in that world, there is] no reason for anyone to ever deploy an AI that's not aligned.
The worst case is that we have no way of building aligned AI, so Alice is reduced to just doing things herself by hand and that world has a giant alignment tax [you lose all the value of using AI if you won’t use unaligned systems].
In reality, we're probably going to be somewhere in between those two extremes. So we could then imagine two approaches to making AI systems aligned:
- Reducing the alignment tax, so that Alice has to incur less of a cost if she insists on her AI being aligned.
- Paying the alignment tax. If I just accept that it's going to be hard to build aligned AI, I could just pay that cost.
I'm mostly going to be talking about reducing the alignment tax, but just to flesh out some options around paying the alignment tax:
You can imagine that one class of strategies is just caring enough to pay the tax. So if you're an AI developer or an AI consumer, you could pay some cost in order to use aligned AI, and that's a way that you can make the longterm future better [by supporting the rise of systems that don’t pose as great a danger as they become more powerful].
You can also try to influence which people are in a position to make those choices. So you could [either try to help people who care about alignment gain key positions in AI development/regulation, or find people who are already in those positions and convince them to care about alignment.]
Another option is to try and coordinate. So if Alice and Bob are in this position, they would both prefer to have AI systems that are doing what they want, but maybe they placed this trade off: they could just both agree. Alice could say: “Look, Bob, I will only deploy an AI that's not doing exactly what I want if you deploy such an AI.”
If we just both keep insisting on aligned AI, we're (roughly) back where we started. And maybe that can make the alignment tax less painful. You can imagine that this would take some work; you’re designing agreements that might make it less painful to pay this tax and then enforcing those agreements.
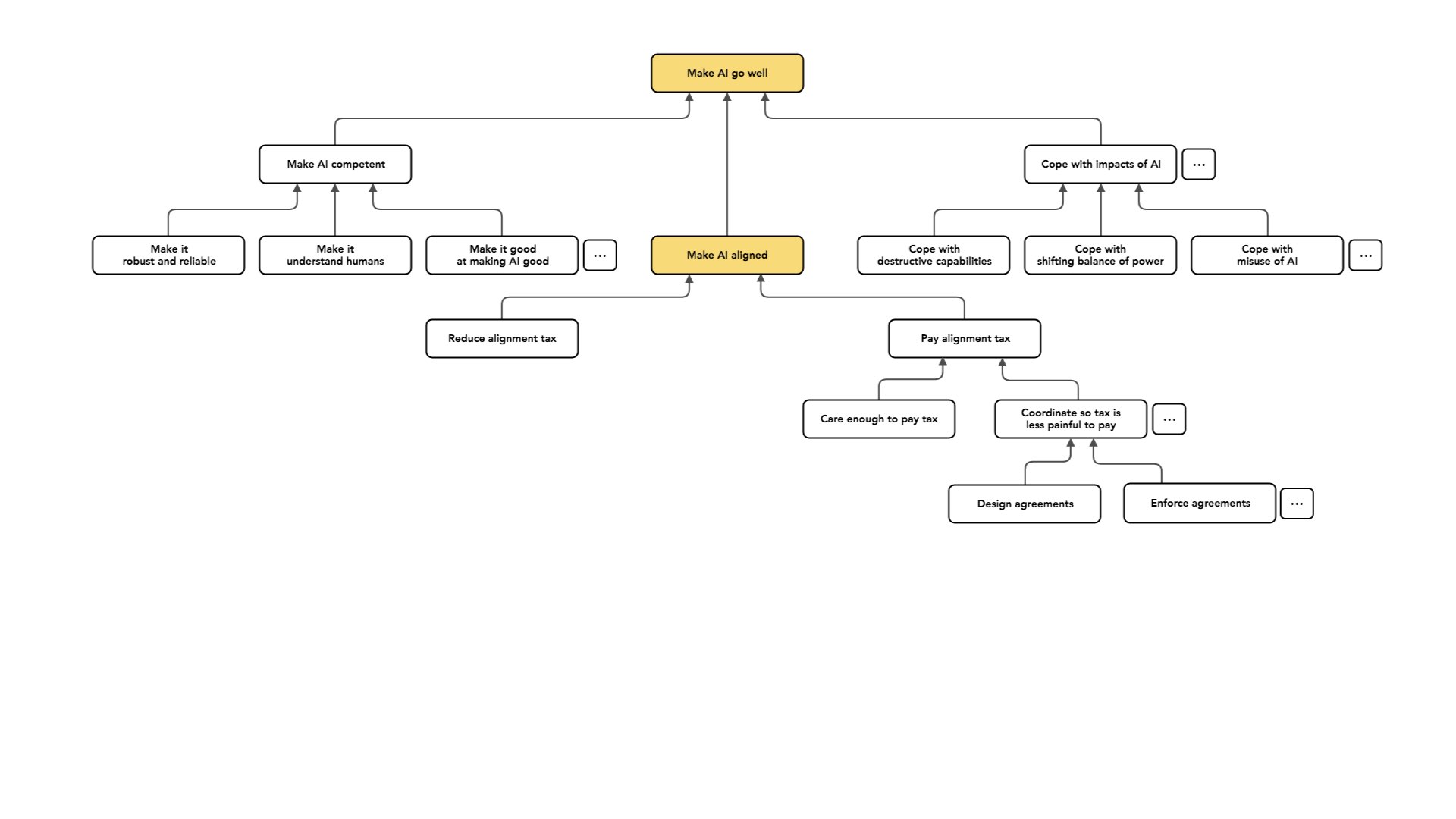
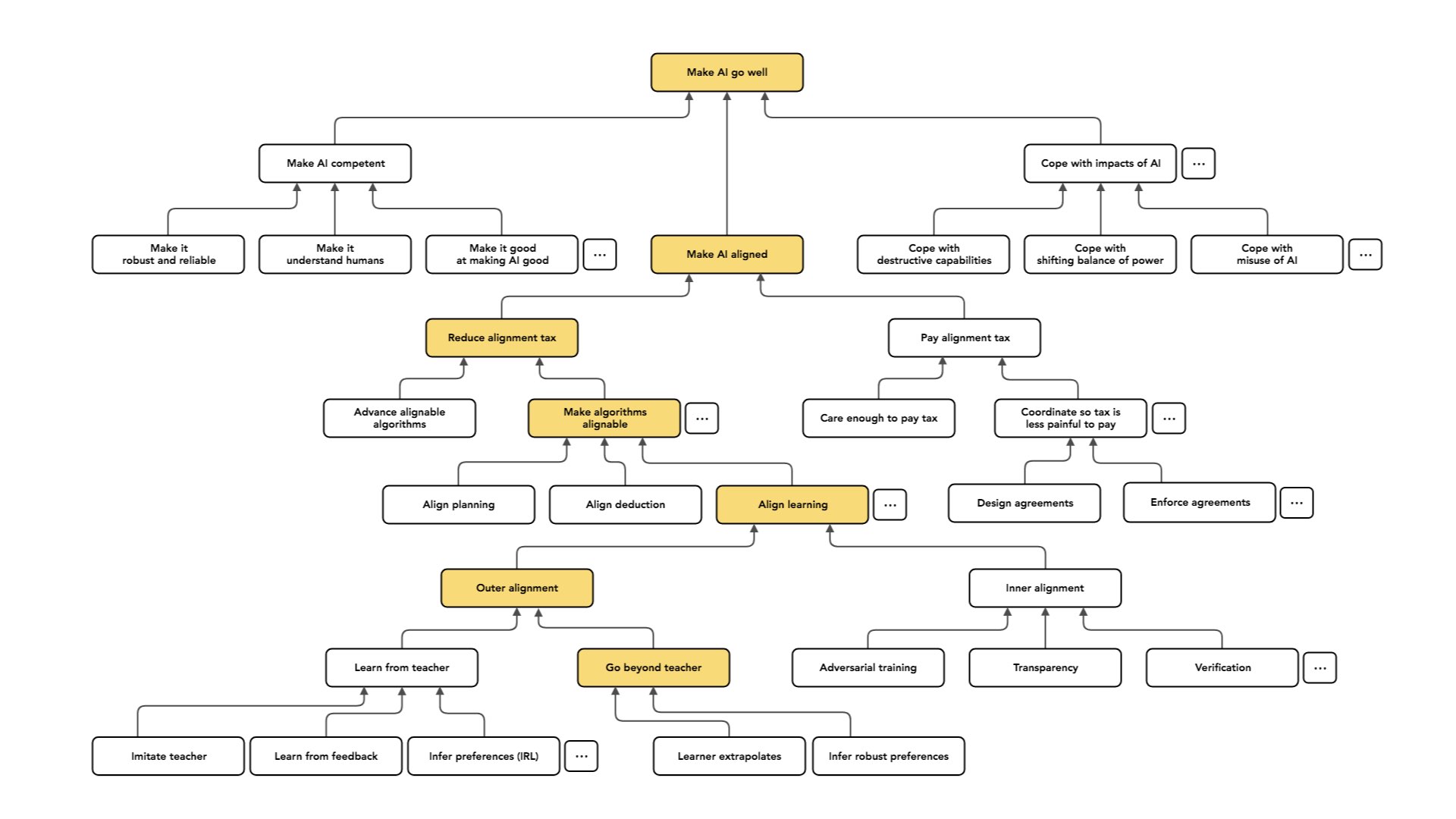
This is what I mostly focus on: how we can do technical work that reduces the alignment tax. You could imagine several different kinds of approaches to this problem. I'm going to talk about two.
One is the idea of having some view about which algorithms are easier or harder to align.
So for example, I might have a view like: we could either build AI by having systems which perform inference and models that we understand that have like interpretable beliefs about the world and then act on those beliefs, or I could build systems by having opaque black boxes and doing optimization over those black boxes. I might believe that the first kind of AI is easier to align, so one way that I could make the alignment tax smaller is just by advancing that kind of AI, which I expect to be easier to align.
This is not a super uncommon view amongst academics. It also may be familiar here because I would say it describes MIRI's view; they sort of take the outlook that some kinds of AI just look hard to align. We want to build an understanding such that we can build the kind of AI that is easier to align.
That's actually not the approach I'm going to be talking about or like not the perspective I normally take.
Normally, I instead ask a question which supposes that we have this kind of algorithm, suppose that we have the black boxes.Is there some way that we can design a variant of those algorithms that's alignable, so that captures or works about as well as the original underlined algorithm but is aligned?
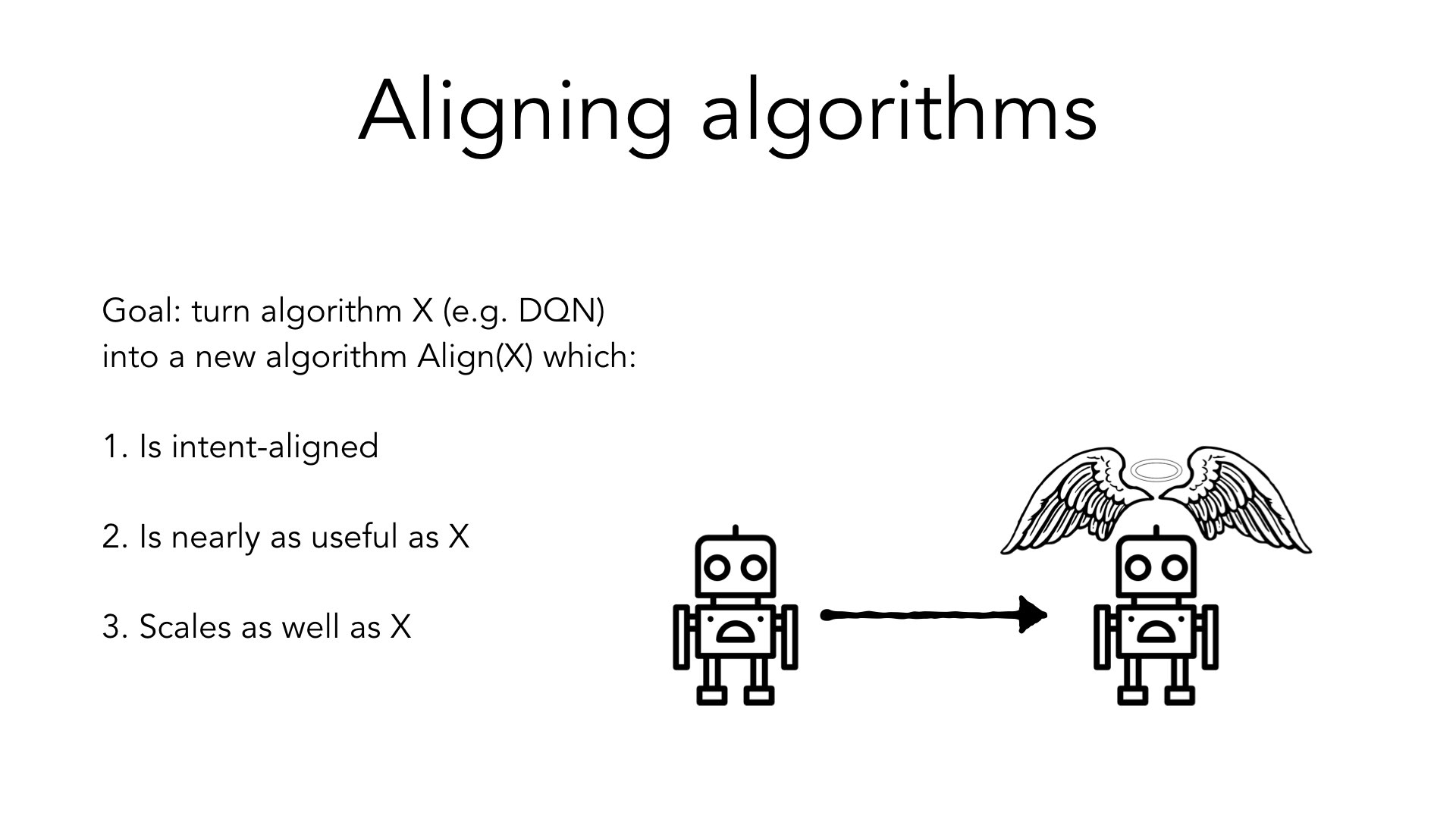
To be a little bit more precise about that, I view the goal of most of my research as starting with an algorithm X that's potentially unaligned (e.g. deep reinforcement learning). I'm then trying to design a new algorithm, “align(X)”, which is intent-aligned, nearly as useful as X, and [as easily scalable] as X. This is the situation I'd like to be in.
If you're in this situation, then Alice, who wants to have aligned AI, can just do the same thing as Bob. But every time Bob would use this potentially unaligned algorithm X, Alice would instead use aligned X. That's the world I want to get to.
I think that the salient feature of this plan is this idea of scalability. You could imagine you have two options for aligning AI.

- One is that as AI improves, we continue to do ongoing work to ensure AI is aligned — and the alignment tax then consists of how much extra work we have to do to make this alignable AI be state-of-the-art.
- The second approach would be to scalably solve alignment for a particular algorithm. So I could say I don't care how good or how deep reinforcement learning gets — I know that regardless, I can [apply a transformation to the algorithm] and end up with an aligned version. And now the alignment tax depends on the overhead of that transformation.
In general, option two is great if it's possible, but it's very unclear whether it's possible. Maybe this depends on how broad a category I’m [referring to when I say] “algorithm.”
I'm not hoping to have a solution which works for any possible kind of AI algorithm. I'm going to look at particular algorithms and say: “Can I form an aligned version of this algorithm?” and hope that as new algorithms appear, I'm able to align them.
In that category, the problem now breaks up by the type of algorithm I want to align.
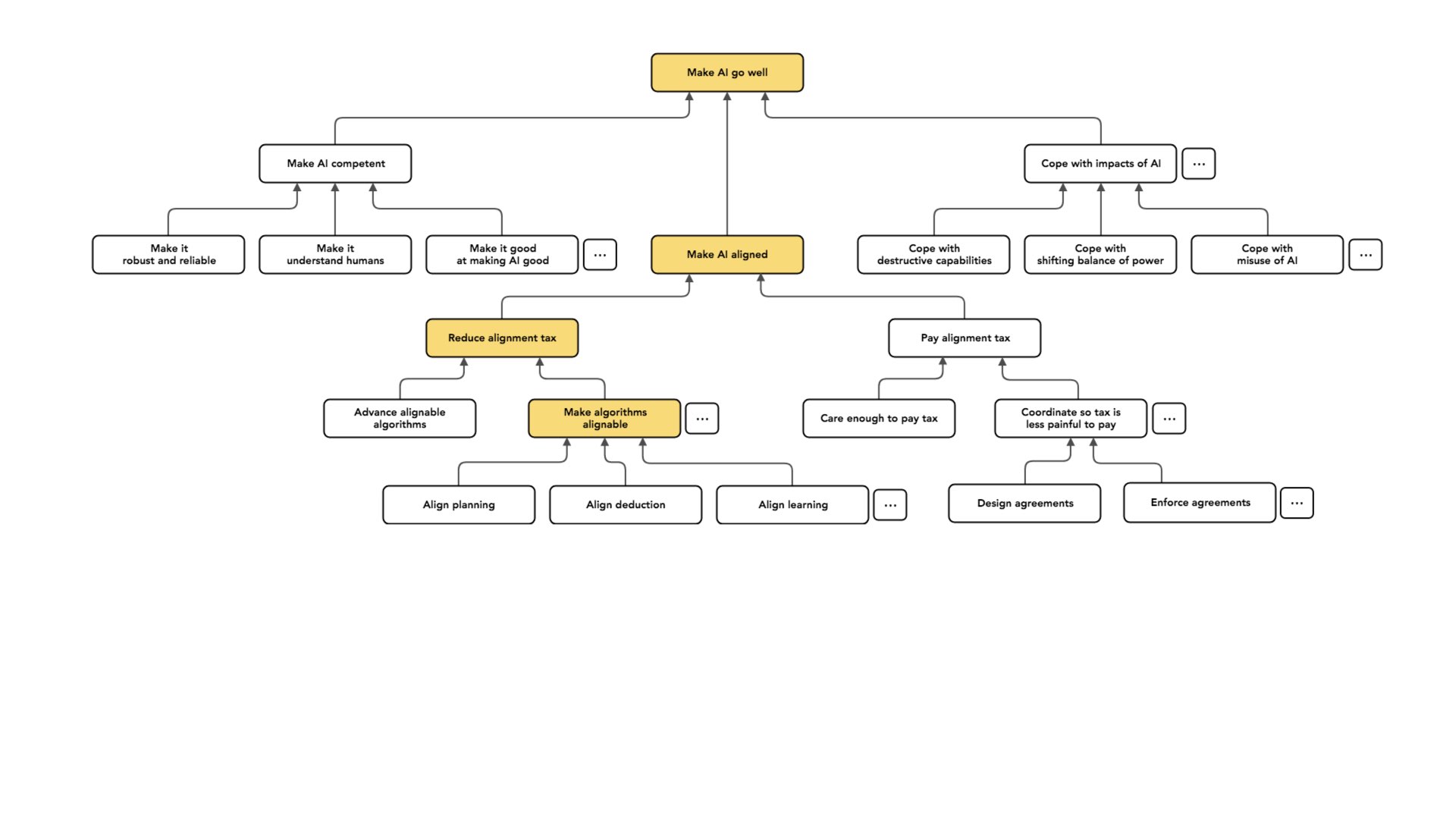
For example, I'm going to talk about planning as an algorithmic ingredient. So an agent can plan in the sense of searching over actions or spaces of actions to find actions that are anticipated to have good effects and then taking the actions that it predicts will have good effects.
That's like an algorithm. It's a really simple algorithmic building block. It introduces potential [obstacles to] alignment if there's a mismatch between what I want and the standard which an AI uses to evaluate predicted effects. It also potentially introduces mismatches: for example, if there's some implicit decision theory in that planning algorithm which I think doesn't capture the right way of making decisions.
So I then have this problem: Can I find a version of planning which is just as useful as the planning I might've done otherwise, but is now aligned and scales just as well?
Similarly, there's this nice algorithm deduction where I start from a set of premises and then use valid inference rules to come up with new beliefs. And I might ask: Is there some version of deduction that avoids alignment failures? The alignment failures in deduction may be a little bit more subtle. I won't be talking about them. And then another algorithm, which looms large right now and is the main subject of my research, is learning, which is kind of like planning at the meta level.
So instead of searching over actions to find one that's good, I'm going to have some way of evaluating whether a possible policy is good (e.g. by playing a bunch of games with that policy and seeing [whether the AI running that policy] wins). And then I'm going to search over policies (e.g. weights for my neural network) to find a policy which performs well, and I'm going to use that one for making decisions in the future.
That's what I mean by learning. And this again introduces this challenge of whether there’s some way to take an algorithm which is potentially unaligned and make an aligned version of learning. That's what we're going to be talking about for the rest of the time. That's the focus of my research.
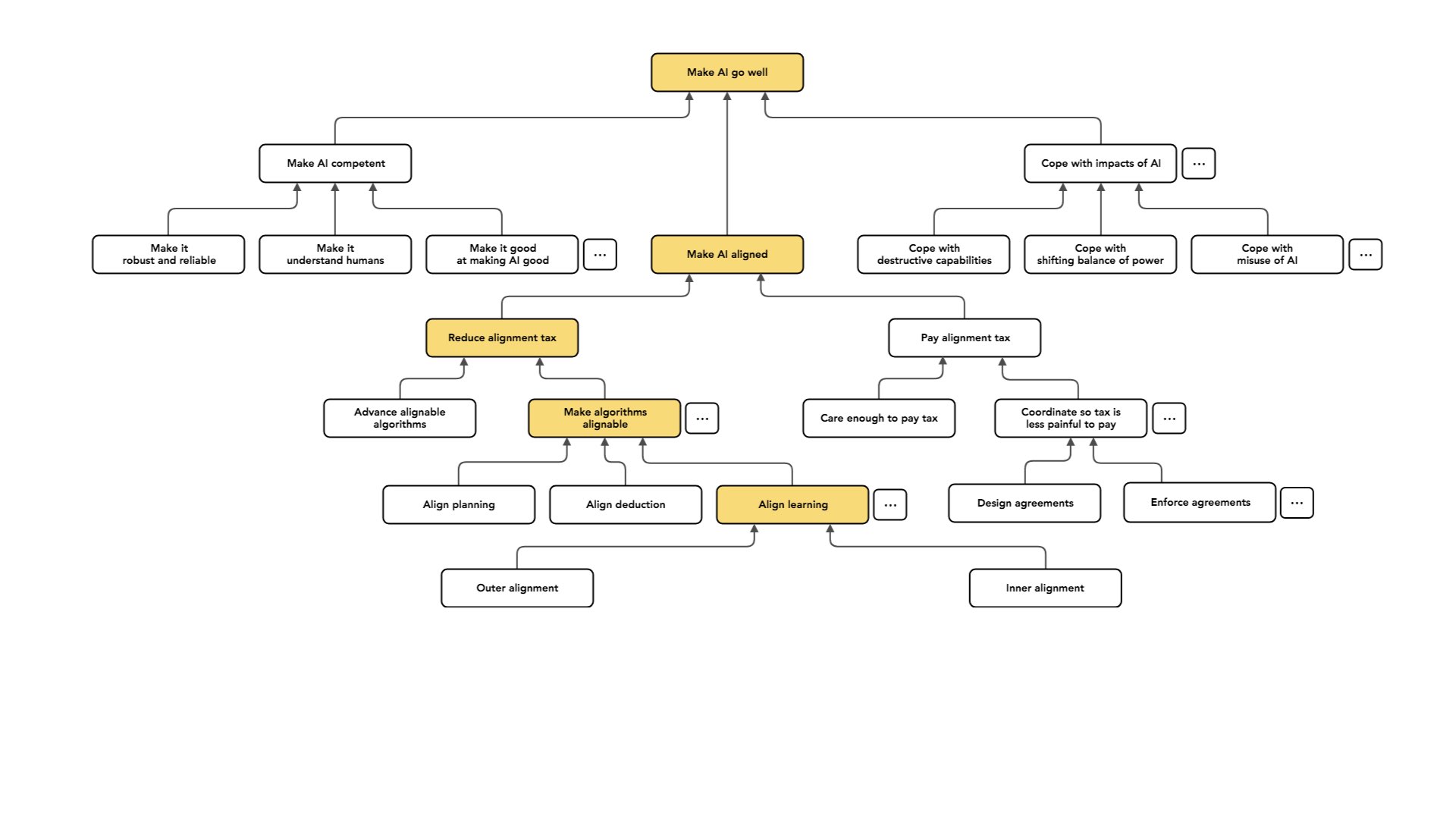
I'm going to again borrow from MIRI and talk about a distinction in this problem — which I think is important and which really helps organize thinking — between “outer alignment” and “inner alignment”.

Roughly speaking, what I mean by “outer alignment” is finding an objective that incentivizes aligned behavior. So when I run a learning process, I have some way of evaluating which policies are good and which policies are bad, and I pick a policy which is good according to that objective.
The first part of the problem is designing that objective so that it captures what I care about — well enough that a policy that performs well on the objective is actually good. So here, my failure mode looks something like Goodhart's law, where I have behavior that isn’t actually good but looks good according to this proxy that I'm using. It looks good according to the standard I'm using to evaluate.
For example, I have an advisor. That advisor is giving me advice. Maybe I pick policies for getting advice based on how good the advice they produce looks, and I end up with bad advice that's just optimized to look good to me. That's the failure mode for outer alignment. The problem is designing an objective that captures what I want well enough.
Then there's the second half of the problem, which is a little bit more subtle, referred to as “inner alignment” — making sure that the policy we ended up with is robustly pursuing the objective that we used to select it.
What I mean by this is… well, I'll again start with an analogy that MIRI likes a lot, where humans were selected over lots of generations to produce large numbers of descendants. But in fact, humans are not primarily motivated day to day by having lots of descendants. So humans instead have this complicated mix of values we care about — art and joy and flourishing and so on — which happened to be [sufficiently well-correlated with survival] in the evolutionary environment that becoming better at pursuing the things we want caused us to have more descendants.
But if you put a human in some very novel situation, they won't keep taking the actions that promote having the maximum number of descendants. There are conditions under which humans will say: “Look, this action will cause me to have more descendants, but I don't care. It will be really unfun. I'm going to do the fun thing instead.”
From our perspective, that's good, because we like fun! From evolution’s perspective, maybe that's a bummer if it was trying to get very large numbers of descendants.
You can imagine facing a similar problem in the learning setting. You could select a policy which performed well on the distribution, but it may be the case that that policy is trying to do something [other than what you wanted]. There might be many different policies which have values that lead to reasonably good behavior on the training distribution, but then, in certain novel situations, do something different from what I want.
That's what I mean by inner alignment. (Again, my research mostly focuses on outer alignment.)
I'm going to say a little bit about the techniques I'm most excited about for inner alignment. One example is adversarial training.
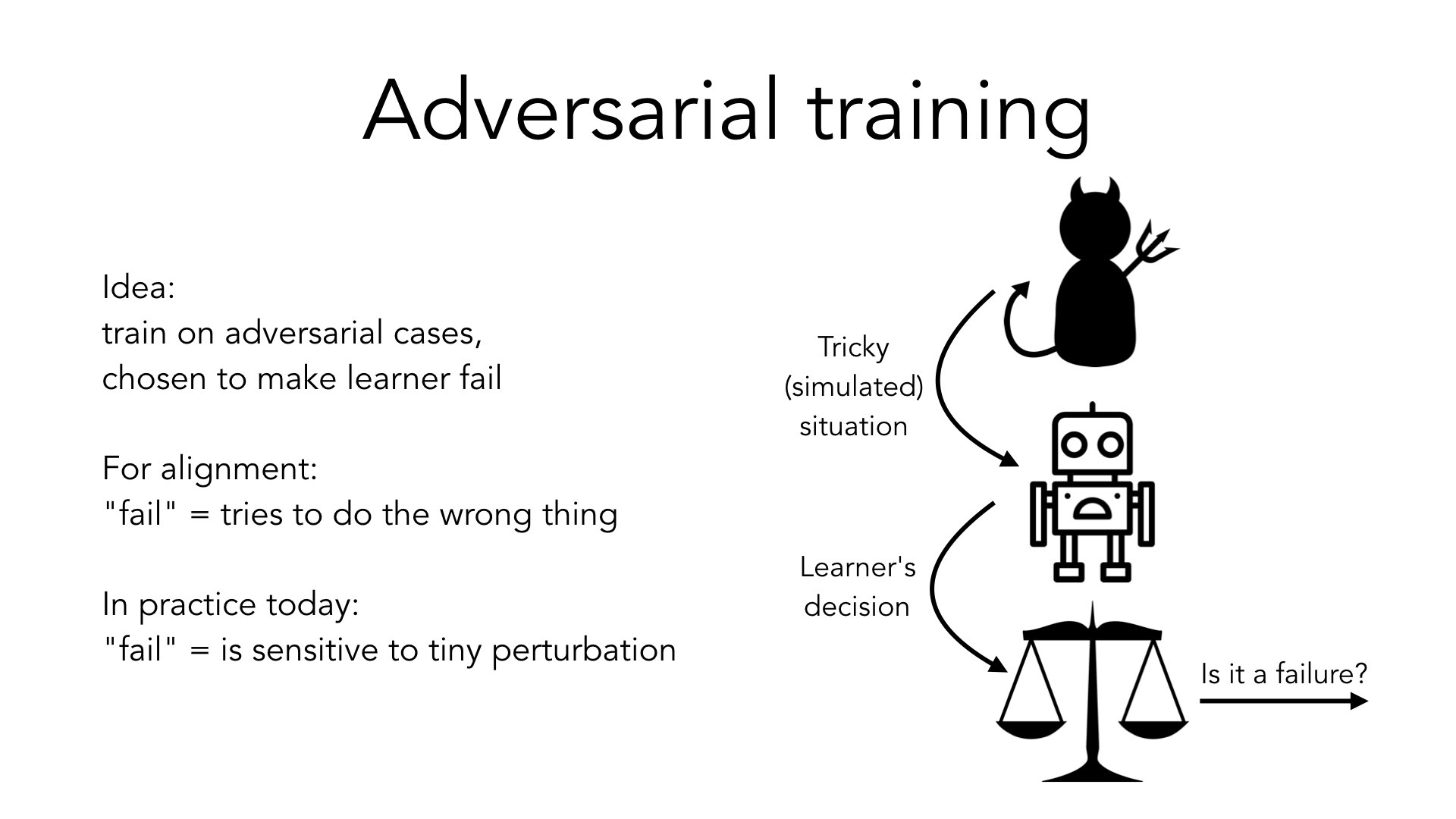
Here’s the idea: if I'm concerned that my system may fail in cases that are unlike the cases that appeared during training, I can ask an adversary to construct cases in which my system is particularly likely to fail, and then train on those. And then we can just repeat this loop. Every time I have a new agent, I ask my adversary: “Okay, now come up with a situation where this would fail.”
The notion of “failure” here is a free parameter that we can choose.
In the case of alignment, failure means it's not trying to do what we want. We’re going to ask the adversary to generate cases like this, where the system isn't trying to do what we want.
In [common AI training work at present], failure most often means something like “the behavior of your model is sensitive to a small perturbation of the input.”
The basic idea is the same between these two cases. There's an open question of how much the techniques which help in one case will help in the other. But the basic framework, the schema, is the same. And this topic is an active focus of research and machine learning; not normally from the alignment perspective, but from the perspective of [finding a system which works well reliably and is robust to different inputs].
There are other possible approaches.
One example: I would like to understand what the policy I've learned is doing. If I understand that, even in a very crude way, I might be able to see that even if a policy [seems to have] a good objective on the training distribution, it would in fact do something very weird under different conditions. It's not really trying to optimize the objective, and so in some strange situation it would do something contrary to my interests.
Again, people mostly study that question today [while thinking] “it would sure be nice to understand something about what these models we're learning are doing.” But the same kinds of research they're doing could be helpful for understanding: is this learning model doing something bad? Would it potentially do something bad in a novel situation?
Another example is verification, where instead of just considering the behavior of my policy on particular examples, I can try and quantify over possible inputs. I can [test situations directly, to find situations where the policy would do badly or to demonstrate that it does well in every case].
Like I said, I mostly work on outer alignment. Here, again, I'm going to make another pairwise distinction dividing the problem into two pieces — [you could think of them as] the easy half and the hard half, or the warm-up and the full problem.
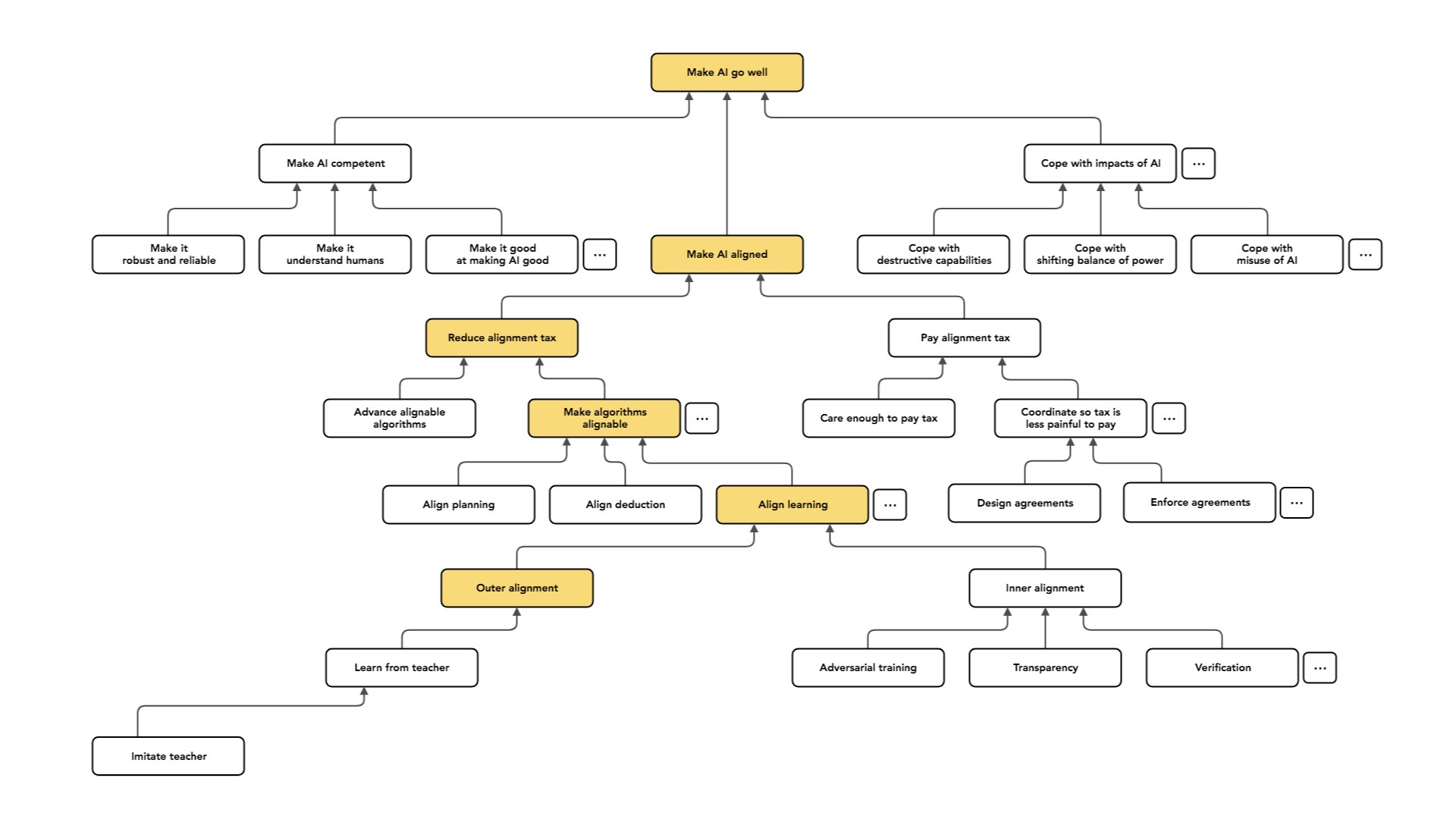
One setting is the case where we have access to some expert that understands the task we want our AI to do very well.
Imagine I have some teacher who is able to demonstrate the intended behavior, and to evaluate the intended behavior — they understand what the AI should be doing. In this case, we have lots of options for constructing an objective that will cause our AI to do the right thing. For example, I could just choose policies that produce behavior that looks very similar to the teacher's behavior.
So if you have a teacher that does what I want, and I want to get an agent that does what I want, I'll just loop over agents until I find one that seems to do the same kind of thing the agent does or the teacher does.
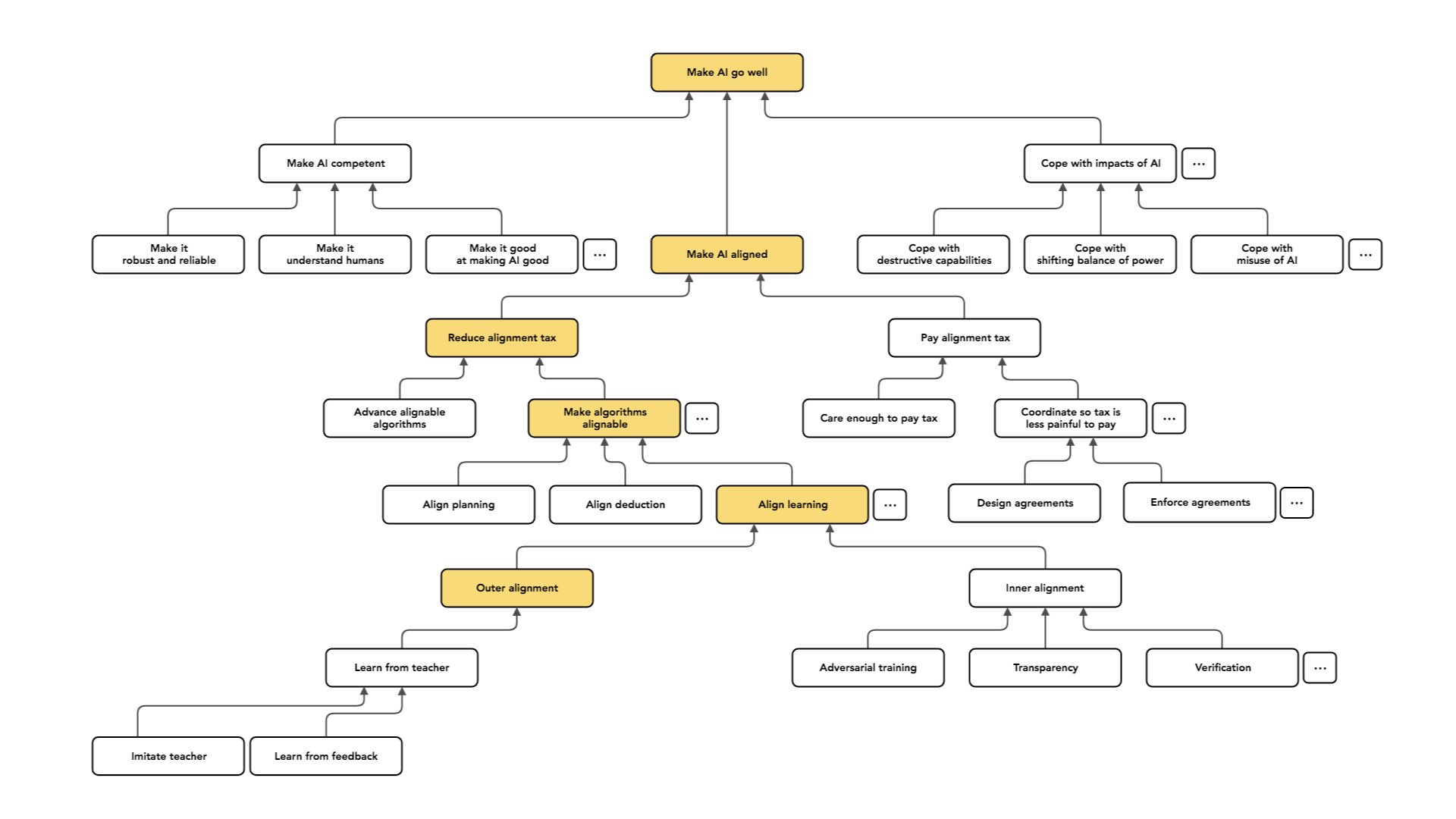
Another option is to have the teacher look at [the AI agent’s] behavior and say whether it was good or bad, and then to search for policies that produce behaviors the teacher thinks are good.
Both of these are cases of imitation and learning from feedback. One of my main difficulties could be that I have access to a teacher, but I want to be able to efficiently use the data the teacher provides. Maybe the teacher is expensive [to work with], and this is the kind of difficulty that looms really large — being efficient about how I use that expert's time, and being careful about how [the teacher’s knowledge] gets transmitted to the agent.
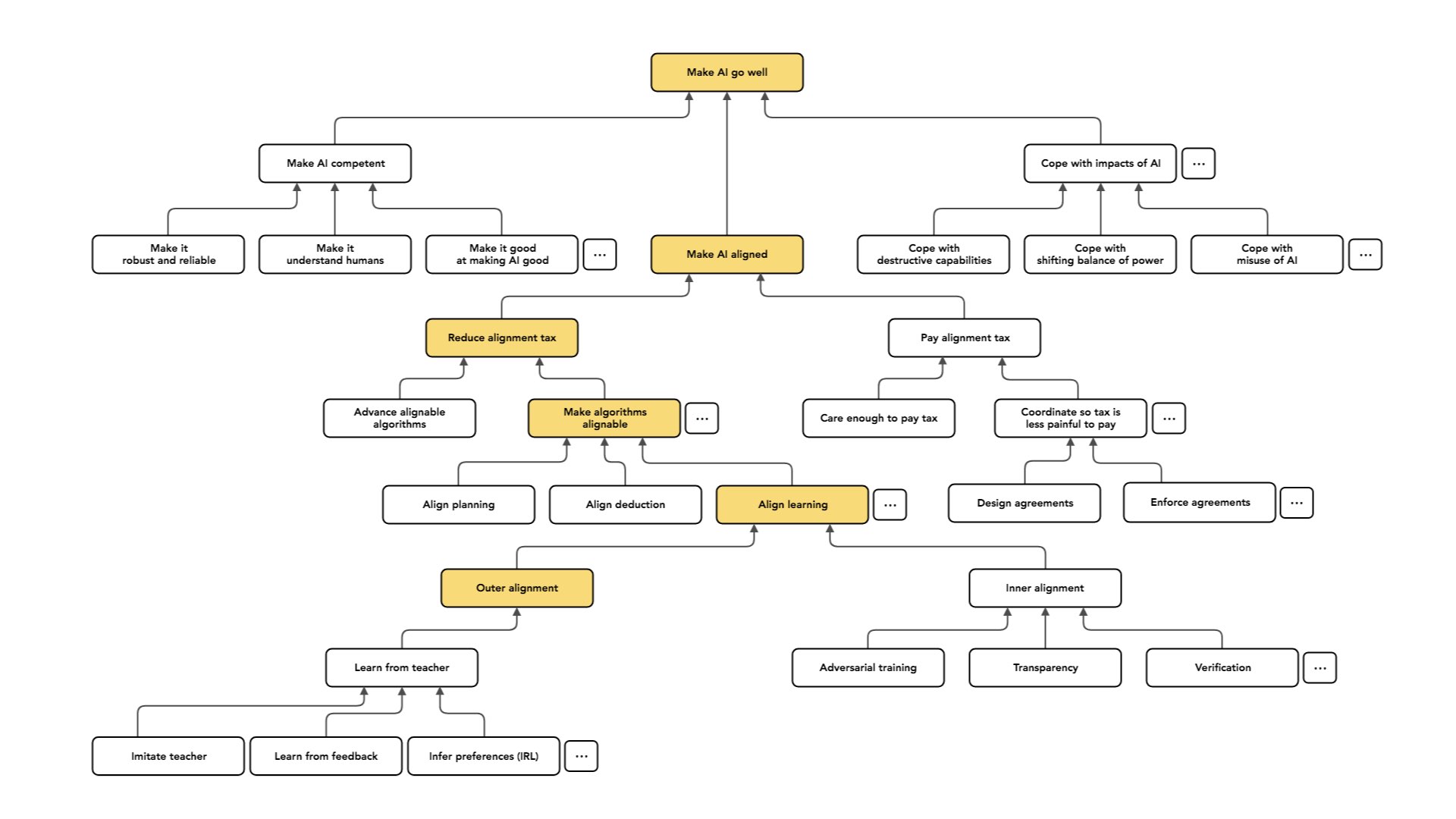
Another option is “inverse reinforcement learning”: looking at the behavior of the teacher, figuring out what values or preferences the teacher seems to be satisfying, and then using those [as values or preferences for the agent].
You can view imitation and learning from feedback as special cases of some more general paradigm. This is going to involve some assumption that relates the preferences of the teacher to their behavior [e.g. assuming that the teacher behaves somewhere close to optimally to satisfy their preferences].
As I said, the easier kind of case is the one where we have a teacher and the teacher is able to exhibit or understand the intended behavior. But the case we care about in the long run is one where we want to build AI systems that are able to make decisions that a human couldn't make, or that understand things about their situation that no available teacher understands.
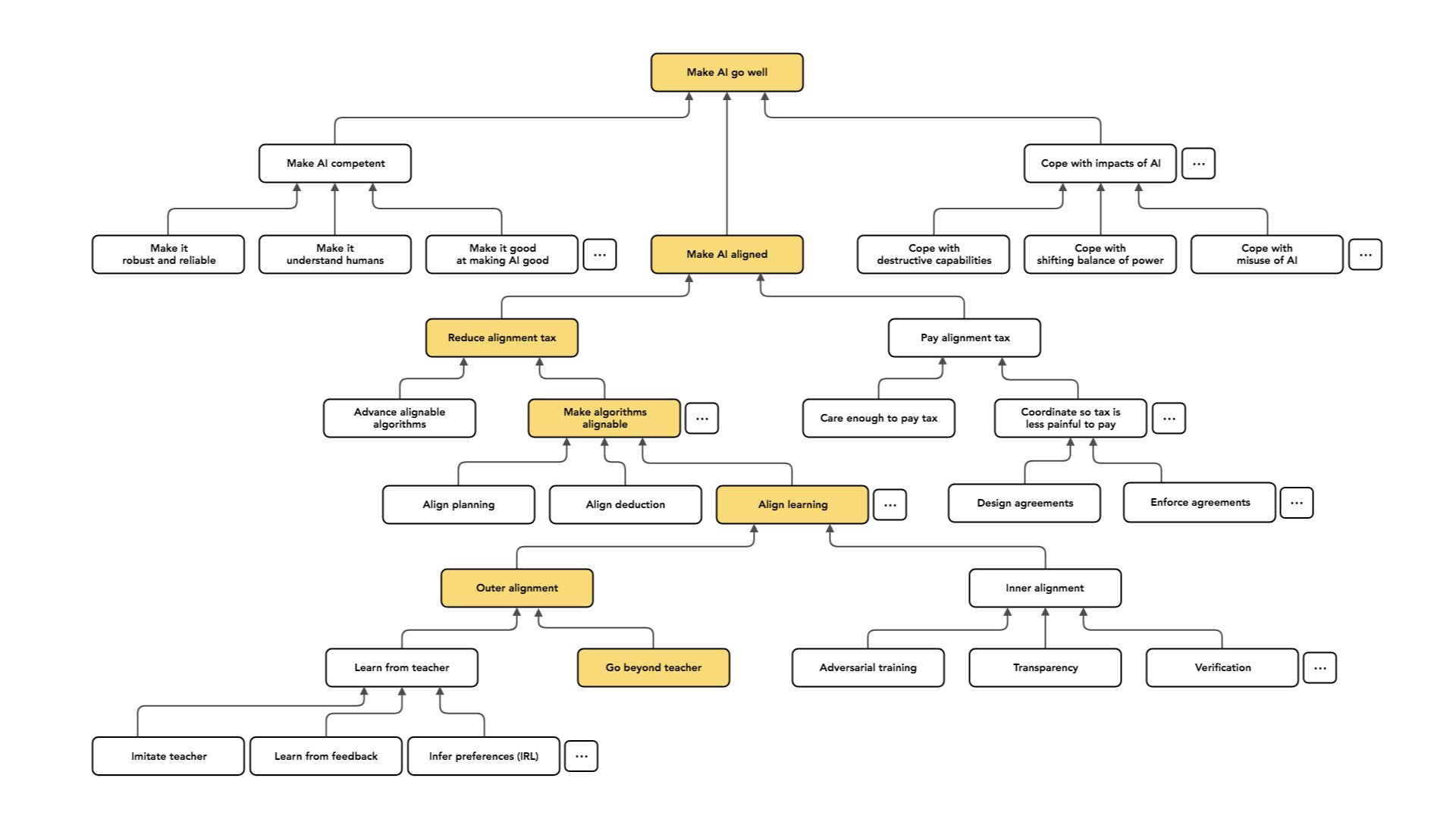
And so the case of learning from a teacher is, in a practical sense, the more immediately relevant one. We have humans who are very good at doing tasks. Today, we mostly want our AI systems to do what humans do but cheaper. In the long run, from the perspective of long-run alignment risk, we care a lot about the case where we want to do things that a human couldn't have done or can’t even understand.
This may be a [type of case] that people concerned about long-run impacts focus on more, relative to people who care about practical applicability. So I'm going to talk about three different approaches to this problem (which, again, aren’t exhaustive).
One approach — which I think is the most common implicit expectation of people in the ML community — is to treat the case where you have a teacher as a “training set,” and then to train a model which will extrapolate from that data to the case where you don't have access to a teacher. So you hope that if your model generalizes in the right kind of way, or if you train it on a sufficiently broad distribution of cases, it will learn the right thing and extrapolate.
I'm not going to say much about this. I think the record so far for this kind of extrapolation is not great. But I think it's a reasonable thing to ask whether it might [work better] as our AI systems get more intelligent.
Another option would be to treat the “learning from a teacher” case as a warm-up. We could do inverse reinforcement learning and try to [figure out] what the teacher’s values were. We can also try to go beyond the teacher and infer what they actually wanted. [The values someone uses to make decisions aren’t the same as the things they actually want to get from those decisions.] In some deeper sense, can we understand which of the teacher's behaviors are artifacts of what they want versus what they value? Can we pull those apart and try to get what [the teacher] wanted, but without the limitations they had?
I think this is a plausible project, but it looks really hard right now.
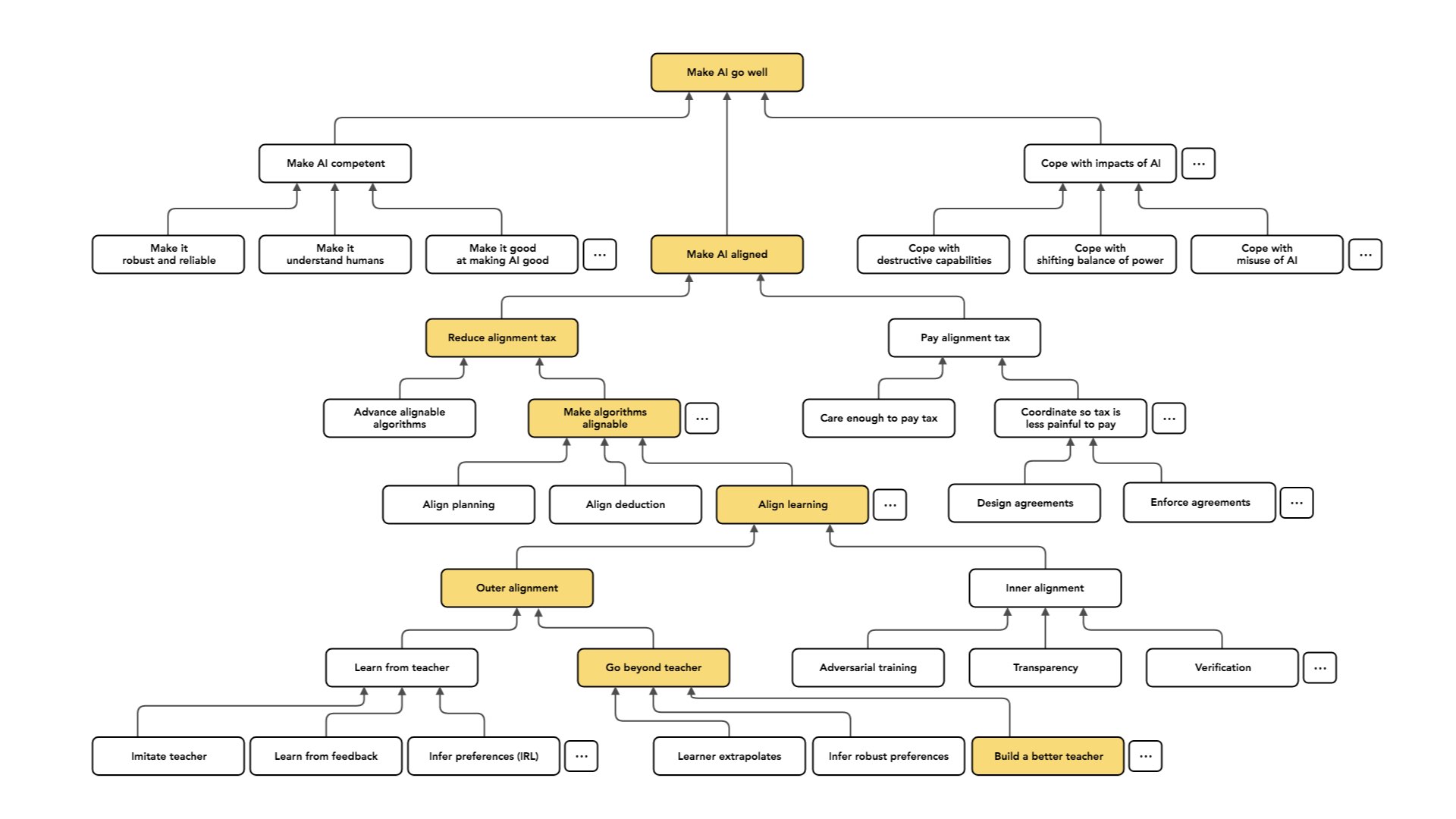
And then a third approach, which also looks hard — but is the one I'm most excited about and most focused on — is to treat learning from a teacher as a building block and say: “Suppose that we can solve that problem well. Is there some way we can use that to directly get what we want in the long term?” We might assume that if we could just build a sequence of better and better teachers, we can train a sequence of better and better agents without ever having to [understand anything that a teacher wouldn’t understand].

So the idea here is that we're asking: where can we get a better teacher? One who understands enough to train the agent? And one place we can get traction is that if you take 10 people, maybe they can solve harder problems than one person can solve.
So if you have 10 people and you ask them to decompose a problem — break it into pieces and divide up the work — they can solve problems that would've been at least slightly beyond the abilities of a single person. And we could hope that the same applies to the AI systems we train.
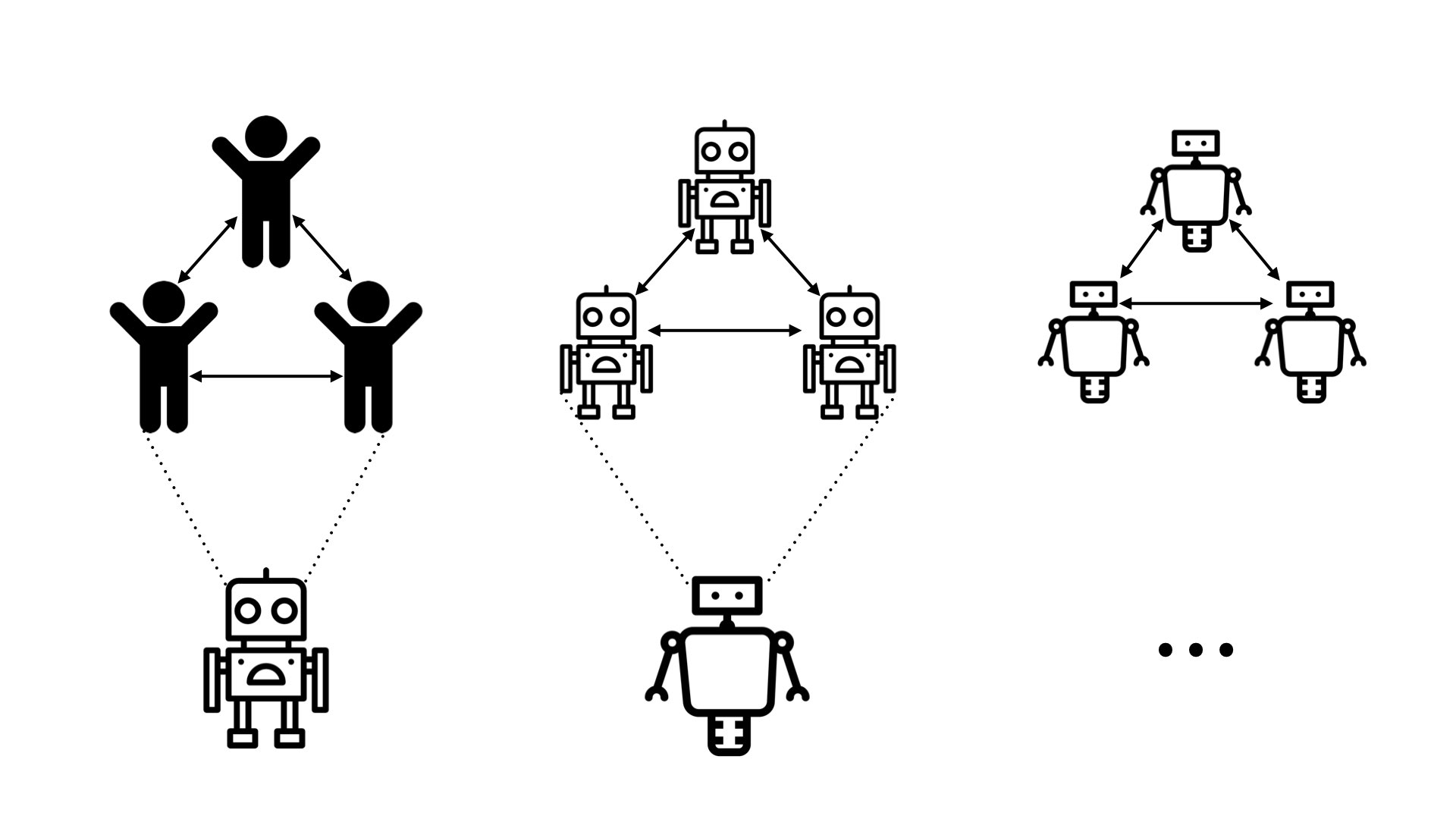
[An overly simple explanation] would be to say: “Rather than taking our initial teacher to be one human and learning from that one human to behave as well as a human, let’s start by learning from a group of humans to do more sophisticated stuff than one human could do.” That could give us an AI, which isn't just “human-level,” but is the level of a human group.
And then we can take that as our building block and iterate on that procedure. We can form a group of these AI systems. Each AI was already as good as a human group. Maybe this group of AI is now better than any group of humans, or is as good as a much larger group. And I can use that [group of AI] as the teacher to train yet another AI system.
If this dynamic consistently goes in the right direction, I can hope to just train a sequence of better and better AI systems — which continue to do what we want [because each group in the sequence was aligned with our original intention]..
That was a broad overview of how I see different parts of the alignment problem relating to each other, and how they fit into the bigger picture. I’m trying to understand [how AI systems actually make decisions] instead of just accepting that we're going to have these crazy opaque black boxes. Let's push on different approaches that don't [come with] the same potential risks [of systems not being aligned with human goals].
When I'm thinking about these kinds of issues, it's really helpful for me to have sort of a big picture in mind of how things hook together, what the separate problems are and how they relate. So that's all I have to say, and I think that leaves us just a few minutes for questions. Thank you.
Nathan Labenz: All right. Thank you very much. First question: since you mentioned Eliezer, my understanding of his personal trajectory going through these sorts of problems was to get stuck on what humans want — and to wonder if there is a coherent answer to that, or if what humans want is sort of inherently contradictory and thus not really answerable by systems. You blew right past that. Are you not worried about that? How do you think about that problem?
Paul: So I guess in this talk I sort of zoomed in enough that I [didn’t cover many parts of my model]. In particular, I didn't talk at all about how you actually sort out any of the ambiguity in what humans want, or in [whose wants we actually want to follow]. I think those are important questions. I don't currently feel like they're the central difficulties [of AI alignment], or at least central difficulties to be resolved by someone like me, with the kind of perspective I'm taking.
I think Eliezer is probably in a broadly similar place; I think he now treats it as hazardous to focus on that aspect of the problem and [prefers to talk about very simple wants] — as in, you want an AI that's just going to, like, make you a sandwich. Can you have an AI that's really just trying to make you a sandwich as well as it possibly can [without incurring alignment risk]?
I think he also thinks that's the most likely step to fail — whether your AI even tries to basically do the right kind of thing. In the context of deep learning systems, he's very concerned about this kind of inner alignment case — for example, the way in which humans are just not even vaguely trying to do what evolution wanted, if you view evolution’s goal [for the human species] to be something like “building humans.”
I obviously can't speak for Eliezer, but that’s my rough take.
Nathan: A couple of questions that have come in from the app. One person is wondering: Do you think it is possible to give AI the ability to understand humans very well without also giving them the capability to make things go very badly?
Paul: I think there are a lot of subtle questions and tradeoffs in the rest of this tree — like what capabilities you think are good or bad [for AI systems to have].
I think some people have the view that this “understanding humans” thing is actually net-negative because — compared to helping us resolve some kinds of problems [that don’t require fully understanding us] — it gives them more ability to influence the world or the trajectory of civilization. I don't have a strong view on that. I think I'm sort of persuaded by the prima facie case that if you're trying to build a system to help you, it seems good for it to better understand what you want.
That’s not the aspect of the problem I've been focusing on — in significant part because I sort of assume that, for better or worse, very sophisticated AI systems will understand humans well enough to be able to both push the world in various directions and also understand, at least very crudely, what we want.
Nathan: Another question from the audience: You mentioned that the track record for AI systems extrapolating from a teacher is not great. Can you give some examples of where that's fallen down?
Paul: In deep learning, some people care a lot about training a system on one kind of case and then having it work immediately on a new kind of case. And I'd say our record so far has not been great on that.
Here’s what I mean by “cases”: a very dumb case is [a basic learning algorithm], like an AI that sorts a list. Let’s say you want your AI to sort a list and you do it [using a neural net that takes unsorted lists as input and produces sorted lists]. You're probably not going to see generalization [among systems that sort lists of different lengths]. If you try and run the algorithm on a list of length 256, it’s just going to go crazy. You have to make pretty strong architectural assumptions, or to really impose something about the structure of the task into the model, in order to have that kind of generalization occur.
That's one example. I think that in general people have been surprised [by how poorly these systems generalize], and one of the big criticisms of deep learning is that when you train it in one case, it only works well in that case. It doesn't tend to work well (yet) in other cases. The big question: is that [difficulty in generalizing] sort of fundamental? Is that like a thing that these systems will always have, or is that something that will go away as they become more powerful — as they get closer to transformative AI?
Nathan: Perfect. How about a round of applause for Paul Christiano? Thanks again.